Создание собственного бесплатного генератора изображений на базе Stable Diffusion v2-1
Генераторы изображений на основе ИИ — идеальный инструмент для творческих личностей с богатым воображением и любовью к технологиям. С помощью моделей Stable Diffusion теперь можно создавать потрясающие, сюрреалистические или совершенно абсурдные визуальные образы, просто набрав текстовое описание. И самое лучшее? Всё это делается с помощью ИИ с открытым исходным кодом, доступного каждому, кто готов экспериментировать и погрузиться в технологии.
Почему стоит создать собственный генератор изображений на базе ИИ?
Конечно, существует множество готовых инструментов, но в создании собственной системы есть что-то особенно привлекательное. Вот почему это стоит сделать:
- Полный контроль: Вы решаете, как это работает — настраиваете выходные данные, регулируете параметры и экспериментируете с новыми функциями.
- Открытый исходный код: Всё полностью в вашем распоряжении для изучения, модификации и создания...
- Работает на пользовательском оборудовании: Используя Google Colab T4 GPU или ваш персональный компьютер, вы можете генерировать качественные изображения без больших затрат.
- Безграничное творчество: Единственное ограничение — ваше воображение. Мечтайте масштабно, экспериментируйте смело и наблюдайте за результатами.
Знакомство с моделью
Stable Diffusion v2-1 — это усовершенствованная модель для генерации изображений по текстовому описанию, разработанная компанией Stability AI на основе предшествующей версии Stable Diffusion v2. Эта модель создана для генерации и модификации изображений на основе текстовых запросов, используя архитектуру латентной диффузии, которая объединяет автоэнкодер с диффузионной моделью.
Обзор модели
Разработка и обучение: Stable Diffusion v2-1 была дообучена на основе оригинальной модели Stable Diffusion v2, пройдя дополнительные 55 000 шагов обучения с последующими 155 000 шагами с различными параметрами безопасности для улучшения производительности и безопасности при генерации изображений. Модель использует фиксированный предварительно обученный текстовый энкодер OpenCLIP-ViT/H, который помогает преобразовывать текстовые запросы в осмысленные визуальные представления.
Технические характеристики:
- Тип модели: Латентная диффузионная модель
- Лицензия: CreativeML Open RAIL++-M
- Поддерживаемые языки: Преимущественно английский
- Данные для обучения: Модель обучена на наборе данных LAION-5B с фильтрацией вредоносного контента
Применение:
Stable Diffusion v2-1 может использоваться в различных областях:
- Искусство и дизайн: Художники могут использовать модель для создания уникальных изображений или улучшения существующего дизайна
- Образовательные инструменты: Служит ресурсом для обучения концепциям генеративных моделей и искусственного интеллекта
- Исследования: Модель предоставляет основу для изучения ограничений и предвзятостей, присущих генеративным технологиям ИИ
Ограничения и этические соображения
Хотя Stable Diffusion v2-1 демонстрирует впечатляющие возможности, но у неё есть определенные ограничения:
- Модель может испытывать трудности с фотореалистичностью и не может точно воспроизводить текст на изображениях
- Обучение проводилось преимущественно на английском языке, что приводит к снижению производительности при работе с неанглоязычными запросами
- Существуют опасения относительно потенциальной предвзятости в генерируемом контенте, отражающем общественные стереотипы из-за набора данных, использованного для обучения
Реализация
Вот как вы можете создать свой собственный генератор изображений на базе ИИ, шаг за шагом. Процесс реализации включает:
- Загрузку модели Stable Diffusion
- Сохранение и локальную загрузку модели
- Создание интерактивного приложения для генерации изображений
1. Загрузка модели
Вариант 1: Использование Transformers
Библиотека Transformers от Hugging Face также предоставляет доступ к моделям.
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
# Загрузка модели из Hugging Face
model_id = "stabilityai/stable-diffusion-2-1"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
# Настройка планировщика и перемещение модели на GPU
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
Сохранение модели
Для сохранения загруженной модели для офлайн-использования:
# Сохранение модели в локальную директорию
pipe.save_pretrained("./stable_diffusion_local")
Вариант 2: Прямая загрузка файлов модели
Вы можете загрузить модель с Hugging Face и использовать её локально.
Скачайте модель и поместите ее в директорию
2. Локальная загрузка модели
Загрузка из локальной директории
При работе офлайн загружайте модель из сохранённой директории:
from diffusers import StableDiffusionPipeline
import torch
# Загрузка модели из локальной директории
pipe = StableDiffusionPipeline.from_pretrained("./stable_diffusion_local", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
3. Основная реализация кода
Создаём интерактивный интерфейс Gradio, который позволяет пользователям вводить запросы, настраивать размеры и просматривать сгенерированные изображения.
Полная реализация:
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import gradio as gr
# Очистка кэша GPU
torch.cuda.empty_cache()
# Загрузка модели
model_id = "stabilityai/stable-diffusion-2-1"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
# Функция генерации изображения
def image_generator(prompt, width=512, height=512):
"""
Генерирует изображение из заданного текстового запроса, используя Stable Diffusion.
Параметры:
prompt (str): Текстовый запрос для генерации изображения.
width (int): Ширина выходного изображения.
height (int): Высота выходного изображения.
Возвращает:
PIL.Image: Сгенерированное изображение.
"""
image = pipe(prompt, width=width, height=height).images[0]
return image
# Создание интерфейса Gradio
with gr.Blocks() as demo:
gr.Markdown(
"""
# Генератор изображений на базе ИИ
Введите запрос , чтобы создавать потрясающие изображения с помощью **Stable Diffusion**.
Настройте размеры и наблюдайте, как ваше воображение оживает!
"""
)
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label=" Введите ваш запрос",
placeholder="например, Футуристический городской пейзаж с неоновыми огнями",
lines=2,
)
width_slider = gr.Slider(
minimum=256, maximum=1024, value=512, step=64, label=" Ширина изображения"
)
height_slider = gr.Slider(
minimum=256, maximum=1024, value=512, step=64, label=" Высота изображения"
)
generate_button = gr.Button(" Сгенерировать изображение")
with gr.Column():
output_image = gr.Image(label=" Сгенерированное изображение")
generate_button.click(
fn=image_generator,
inputs=[prompt_input, width_slider, height_slider],
outputs=output_image,
)
# Запуск приложения
demo.launch()
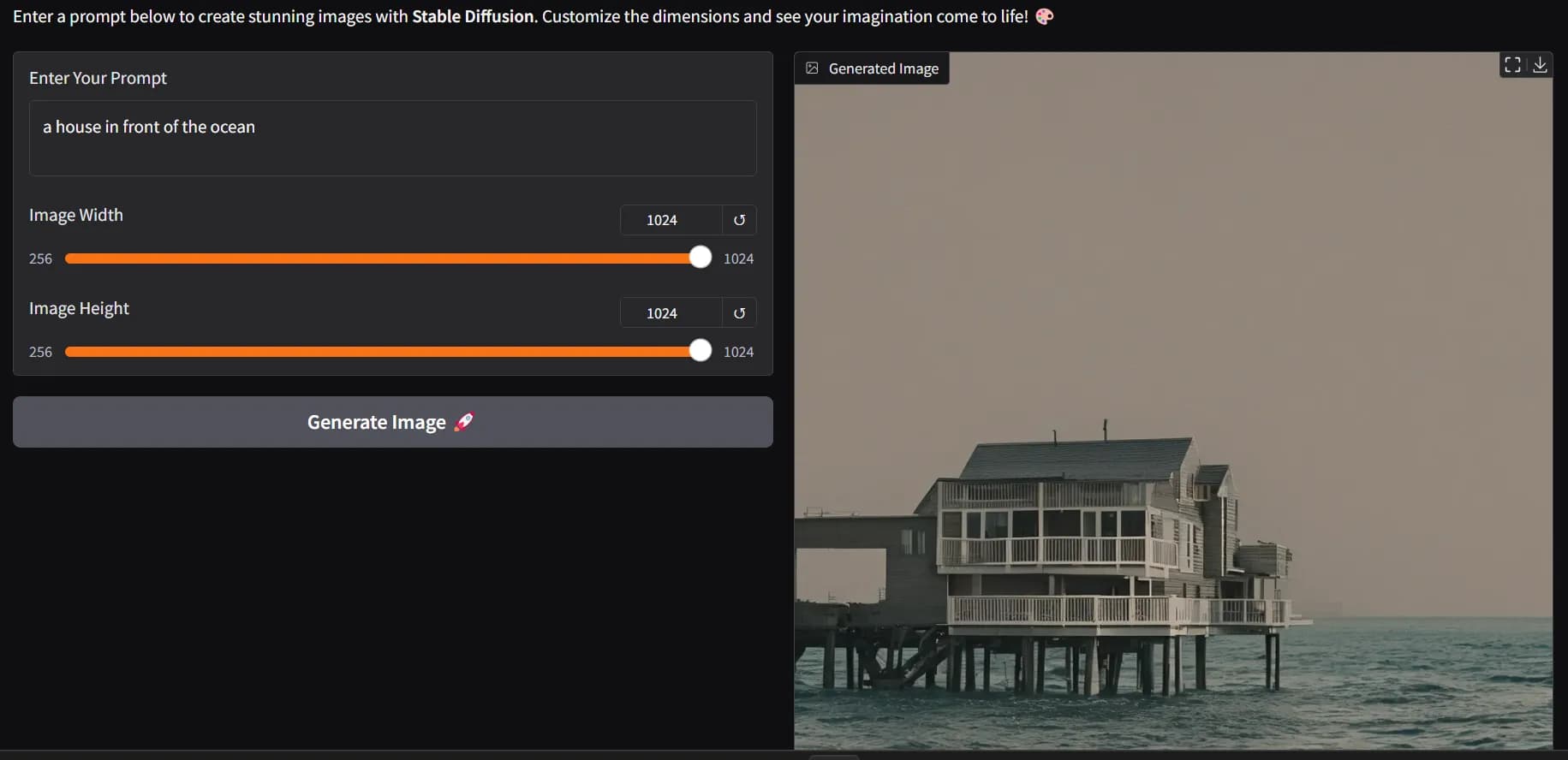
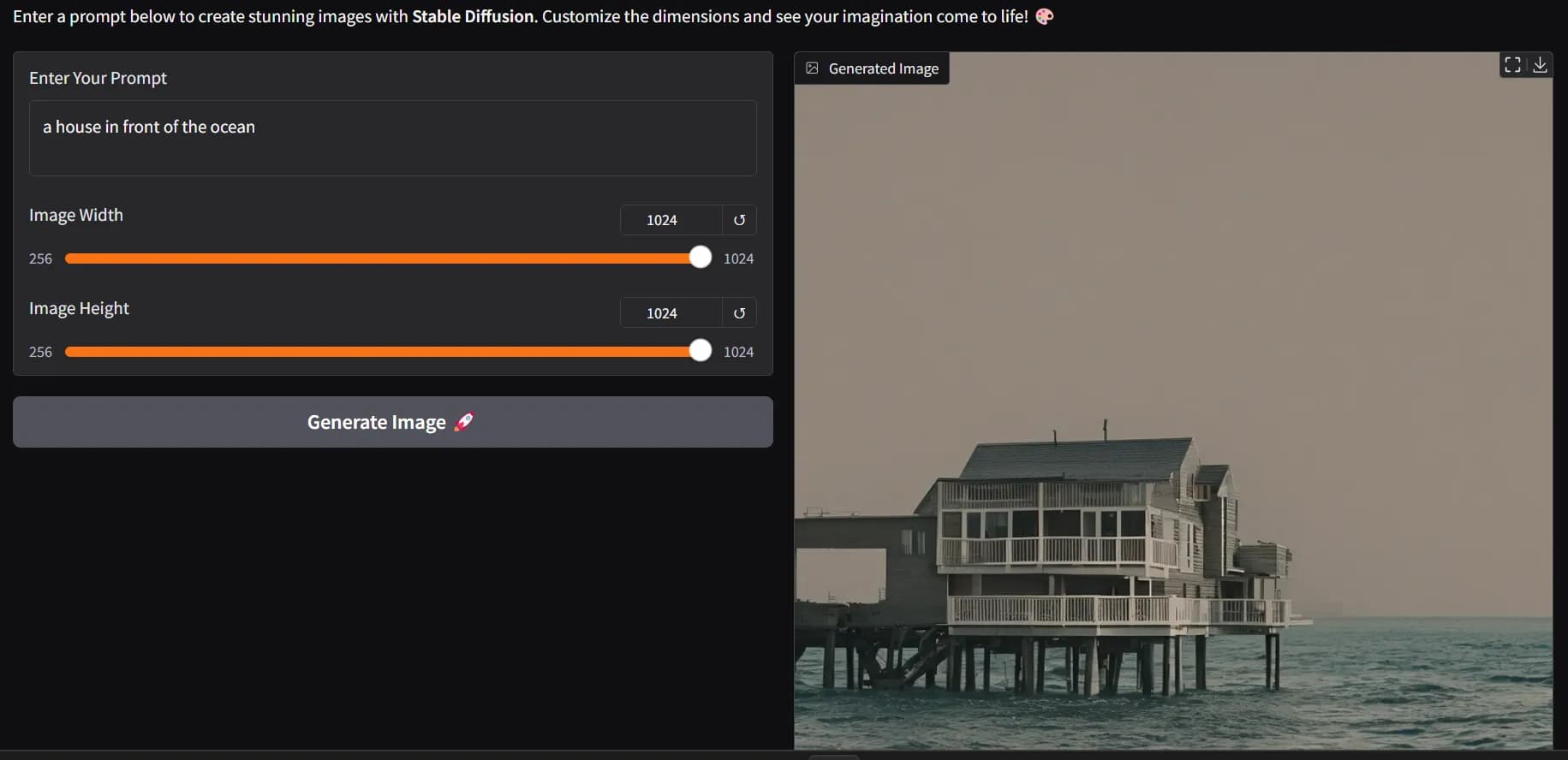
Выходное изображение:
Промт: дом перед океаном
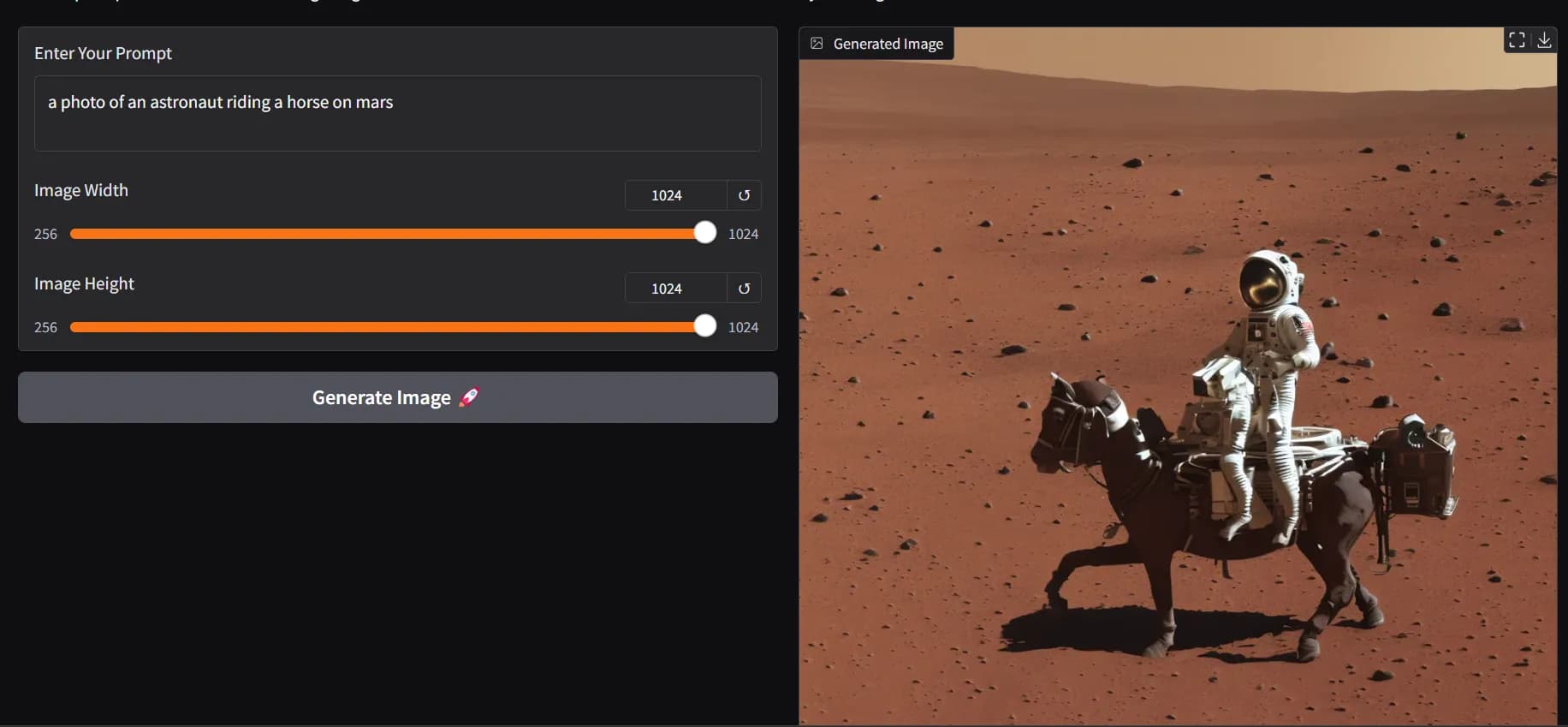
Промт: фотография астронавта, скачущего на лошади по Марсу
Этические соображения
Хотя генераторы изображений на базе ИИ, такие как Stable Diffusion, предлагают огромный творческий потенциал, они также сопряжены с этическими проблемами и практическими ограничениями. Важно понимать эти аспекты для ответственного использования технологии.
Авторское право и владение
- Кому принадлежат изображения, созданные ИИ? Этот вопрос становится ещё более сложным, если модель обучалась на защищённых авторским правом работах без явного разрешения
- Всегда проявляйте осторожность при использовании изображений, сгенерированных ИИ, в коммерческих целях
Дезинформация и злоупотребление
- Изображения, сгенерированные ИИ, могут быть использованы для создания дипфейков или вводящего в заблуждение контента
- Это вызывает опасения по поводу распространения ложных нарративов или нанесения ущерба репутации отдельных лиц
Предвзятость в результатах
- Тренировочные данные существенно влияют на результаты. Если набор данных предвзят, результаты могут непреднамеренно закреплять стереотипы или исключать определенные стили и перспективы
Влияние на окружающую среду
- Обучение и запуск моделей ИИ требуют значительных вычислительных ресурсов, что способствует выбросам углерода
- Выбор энергоэффективных настроек или использование общих ресурсов, таких как Google Colab, может помочь смягчить это воздействие
ИИ генераторы изображений делают творчество более доступным, делая его доступным для каждого, у кого есть идея. Независимо от того, являетесь ли вы художником, экспериментирующим с новыми концепциями, владельцем бизнеса, создающим визуальный контент, или энтузиастом технологий, исследующим ИИ, этот инструмент позволяет воплотить ваше воображение в жизнь.
Благодаря открытому исходному коду и возможности работать на GPU Google Colab T4 или любой пользовательской системе, Stable Diffusion устраняет барьеры для инноваций. Погрузитесь в мир ИИ-искусства и дайте волю своему творчеству!