DeepSeek-V3: Революционная и высокопроизводительная языковая модель с низкой стоимостью обучения
Сегодня мы рассмотрим увлекательную тему: DeepSeek-V3 – новую языковую модель с низкой стоимостью обучения и высокой производительностью.
DeepSeek-V3 – это мощная языковая модель с открытым исходным кодом, выпущенная в декабре 2024 года.
Недавно вышел технический отчет о данной модели, который довольно объемный – более 50 страниц.
Параметры
DeepSeek-V3 представляет собой языковую модель на основе архитектуры Mixture-of-Experts (MoE) с 671 миллиардом параметров, из которых 37 миллиардов активируются для каждого токена. Модель разработана для эффективного вывода и экономичного обучения.
Стоимость обучения
Далее рассмотрим вопрос, который волнует всех – стоимость.
Предварительное обучение DeepSeek-V3, использовало 14,8 триллиона токенов, затрачивая 180 тысяч часов работы GPU H800 на триллион токенов. При использовании 2048 GPU H800 обработка одного триллиона токенов заняла 3,7 дня.

Полное обучение (включая расширение контекста и пост-обучение) потребовало 2,788 миллиона часов работы GPU в течение двух месяцев. При стоимости $2 за час работы GPU общая стоимость обучения составила $5,576 миллиона.
Для модели такого масштаба стоимость удивительно низкая. Это достижение обусловлено применением следующих методов оптимизации, включая FP8 и другие меры по повышению эффективности.
Архитектура модели
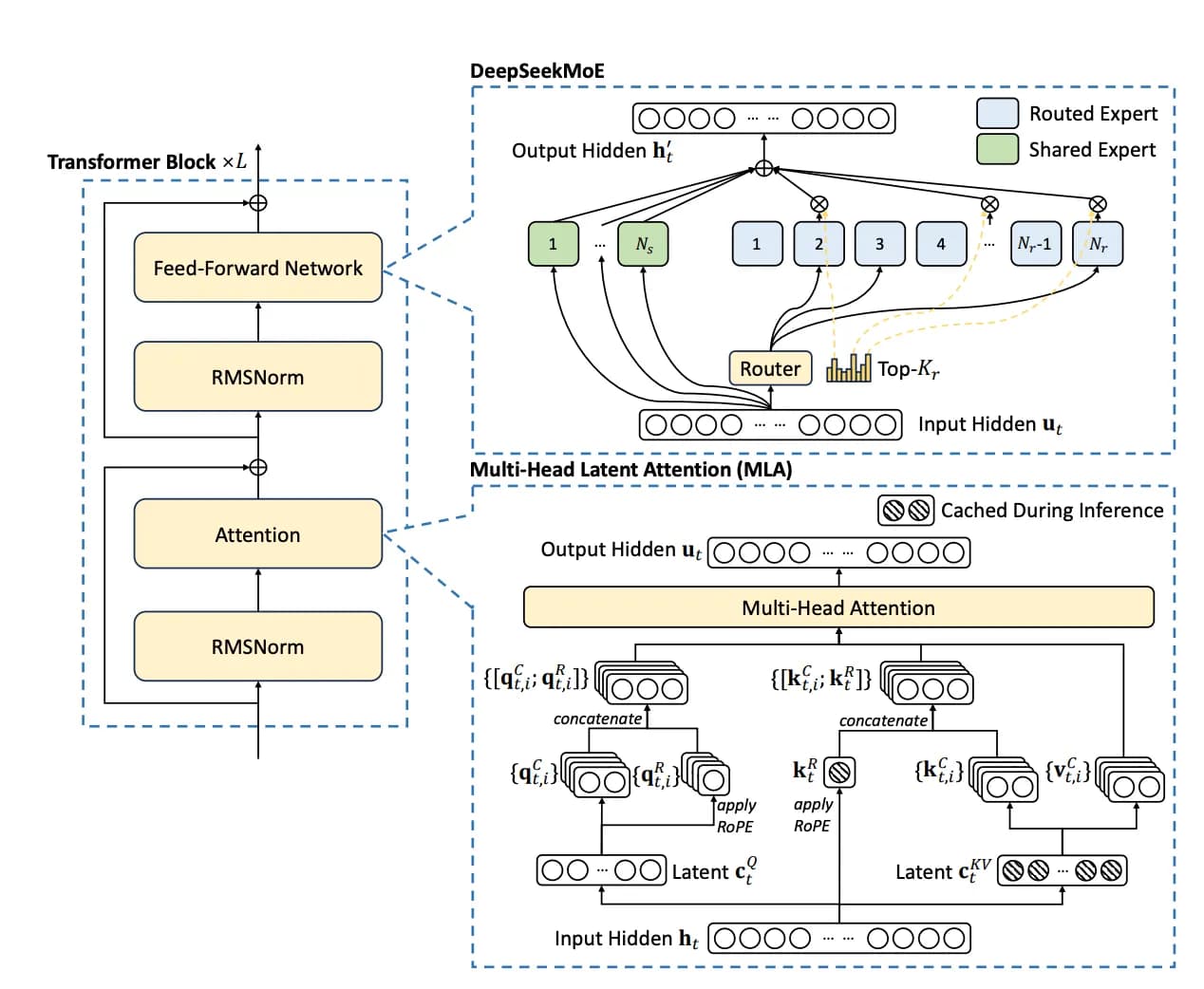
DeepSeek-V3 использует Multi-head Latent Attention (MLA) и архитектуру DeepSeekMoE, которые были подтверждены в DeepSeek-V2 как эффективные и высокопроизводительные решения.
- Multi-head Latent Attention (MLA): Использует сжатие низкого ранга для уменьшения размера кэша ключ-значение (KV) во время вывода, сохраняя производительность, сравнимую со стандартным Multi-Head Attention (MHA).
- DeepSeekMoE: Объединяет общие и маршрутизируемые экспертные модули для лучшего использования параметров модели. Также вводит подход балансировки нагрузки без вспомогательных потерь, который решает проблемы традиционного дисбаланса MoE.
Предварительное обучение
Новая цель обучения: Multi-Token Prediction (MTP)
Основная идея MTP заключается в том, что во время обучения модель не только предсказывает следующий токен (как традиционные языковые модели), но также предсказывает несколько последующих токенов в последовательности, тем самым увеличивая плотность обучающего сигнала и улучшая эффективность использования данных.
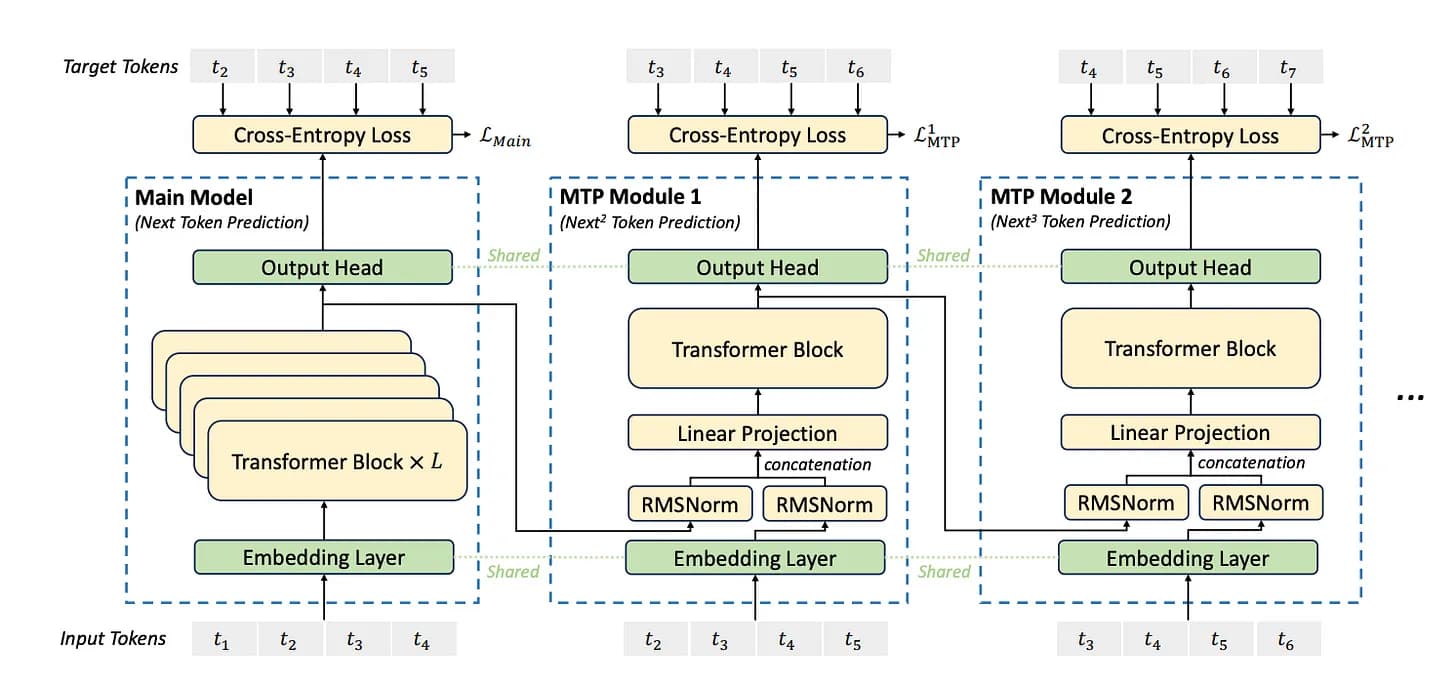
Модули MTP совместно используют параметры слоя вложений и выходного слоя во время обучения, уменьшая использование памяти, и могут применяться для спекулятивного декодирования во время вывода для ускорения генерации.
Обучение с низкой точностью: FP8 Framework
DeepSeek-V3 использует тонкую квантизацию (например, группировка значений активации в плитки 1x128 и весов в блоки 128x128) для преодоления ограничений динамического диапазона FP8.
Это первый случай столь широкого применения FP8 в известной языковой модели.
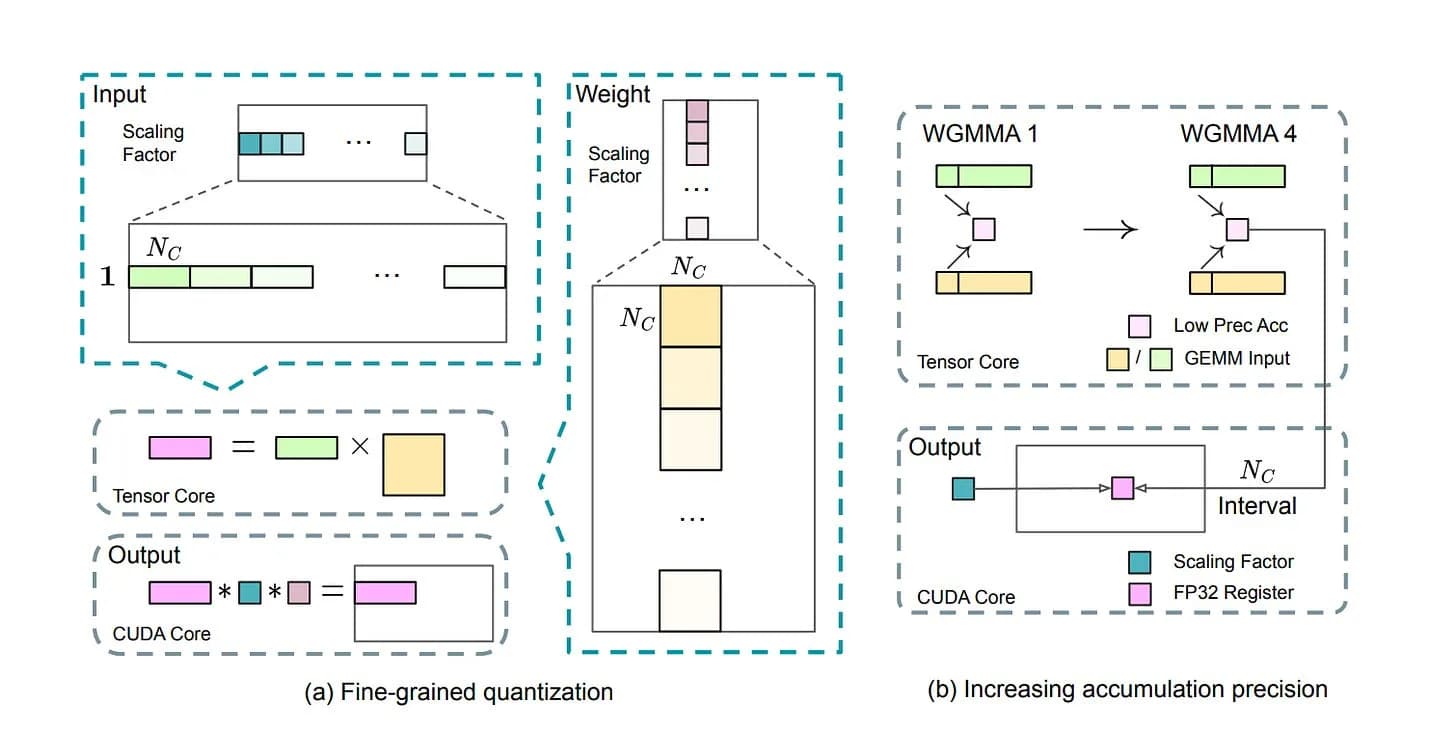
Он также применяет высокоточное накопление на ядрах CUDA. Кроме того, он сжимает активации и состояния оптимизатора в форматы низкой точности (FP8 и BF16), что значительно снижает накладные расходы на память и коммуникации.
Оптимизация эффективности обучения
DeepSeek-V3 использует алгоритм DualPipe – эффективную технику конвейерного параллелизма, которая уменьшает конвейерные пузыри и скрывает большую часть накладных расходов на коммуникацию, перекрывая их с вычислениями во время обучения. Это обеспечивает возможность масштабирования модели с сохранением мелкозернистых экспертов между узлами и поддержанием практически нулевых затрат на all-to-all коммуникацию, пока соотношение вычислений и коммуникаций остается постоянным.
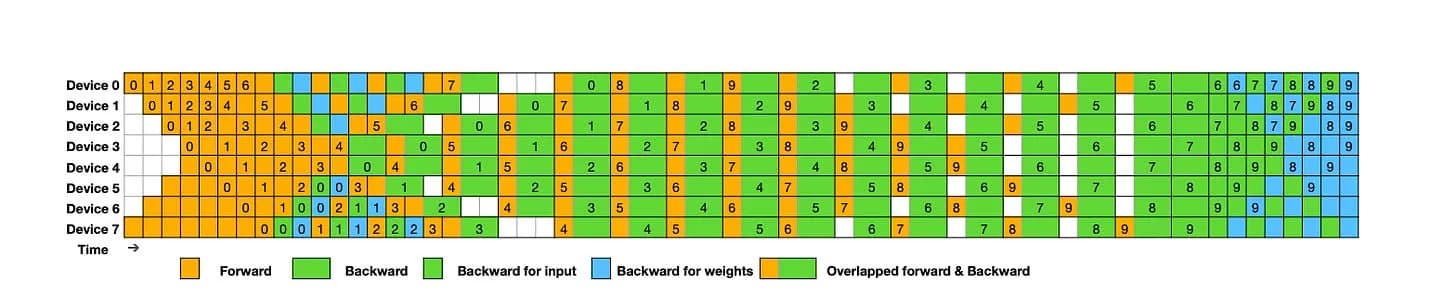
Для оптимизации инфраструктуры DeepSeek-V3 использует InfiniBand (IB) для межузловой коммуникации и NVLink для внутриузловой коммуникации, повышая эффективность распределенного обучения в больших масштабах. Также модель использует настраиваемые ядра all-to-all коммуникации между узлами для снижения латентности.
Гибридная параллельная структура обучения
DeepSeek-V3 использует гибридную архитектуру, объединяющую 16-канальный конвейерный параллелизм (Pipeline Parallelism, PP), 64-канальный экспертный параллелизм (Expert Parallelism, EP) и параллелизм данных ZeRO-1 (Data Parallelism, DP) для повышения эффективности распределенного обучения.
Модель также тщательно оптимизирует использование памяти во время обучения, устраняя необходимость в затратном тензорном параллелизме (Tensor Parallelism, TP), что помогает сделать крупномасштабное обучение более доступным.
Возможности работы с длинным контекстом
После фазы предварительного обучения DeepSeek-V3 использует YaRN для расширения контекста и проходит два дополнительных этапа обучения. В течение этих этапов контекстное окно постепенно расширяется с 4K до 32K, а затем с 32K до 128K.
Пост-обучение
Фаза пост-обучения проводится в два этапа:
- Сначала модель дообучается на высококачественных данных с использованием Supervised Fine-Tuning (SFT) для лучшего соответствия человеческим предпочтениям и потребностям приложений.
- Затем применяется обучение с подкреплением (Reinforcement Learning, RL), сочетающее как правило-ориентированные, так и модельно-ориентированные модели вознаграждения вместе со стратегиями оптимизации, такими как Group-Relative Policy Optimization (GRPO), для дальнейшего улучшения генеративных способностей модели.
Дополнительно используется дистилляция знаний для передачи способностей к рассуждению от серии DeepSeek-R1 к DeepSeek-V3, интегрируя длинные цепочки рассуждений (Chain-of-Thought, CoT) в модель.
Вывод
Языковые модели обычно используют двухэтапный процесс вывода.
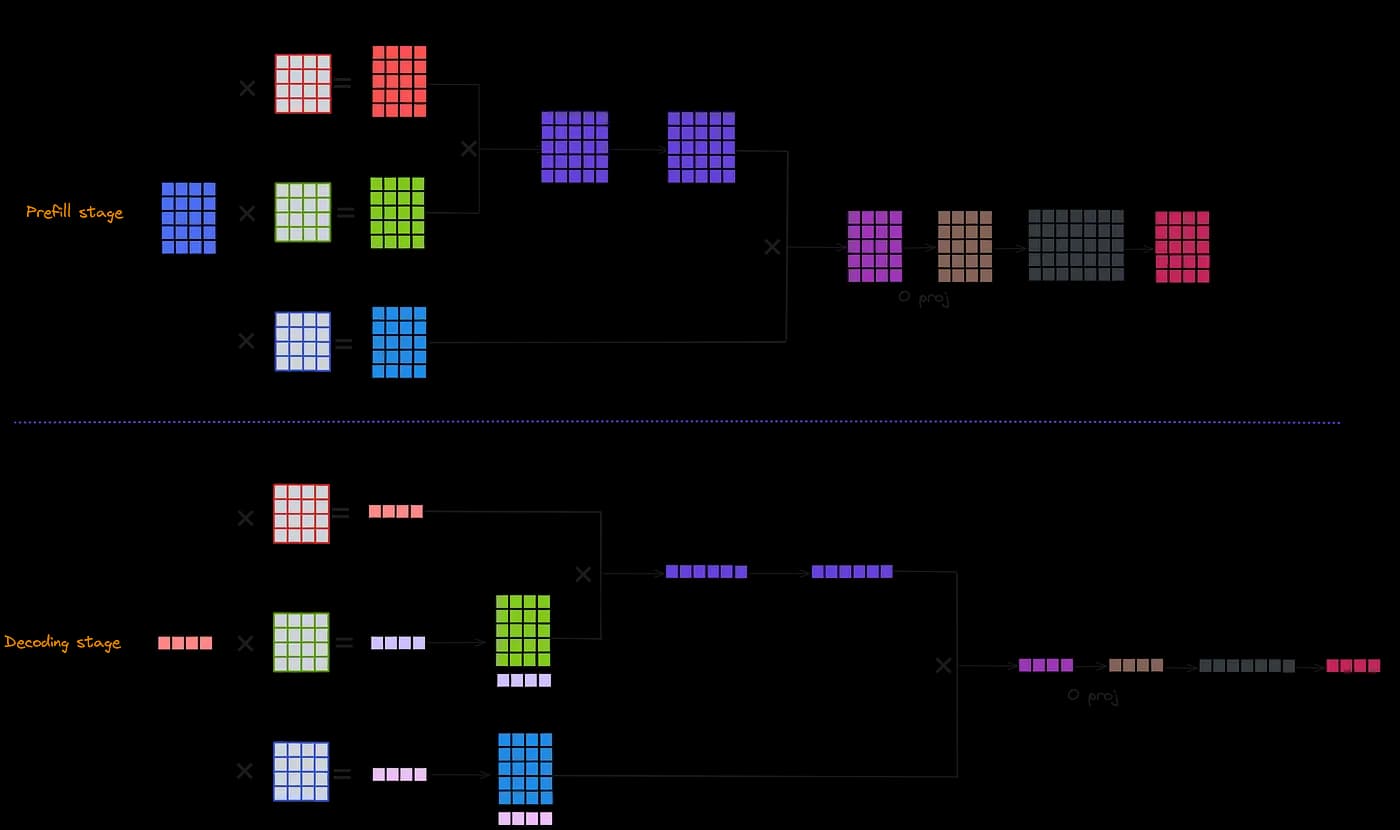
На этапе предварительного заполнения DeepSeek-V3 работает на минимальном блоке из 4 узлов (32 GPU), используя тензорный параллелизм (TP) с параллелизмом последовательностей (SP), параллелизмом данных (DP) и экспертным параллелизмом (EP) для повышения вычислительной эффективности. Модуль MoE использует 32-канальный экспертный параллелизм (EP32) и комбинирует InfiniBand и NVLink для обеспечения быстрой межузловой и внутриузловой коммуникации.
На этапе декодирования DeepSeek-V3 расширяется до 40 узлов (320 GPU) и выделяет GPU специально для обработки избыточных и общих экспертов, оптимизируя эффективность через point-to-point коммуникацию и технологию IBGDA.
Для обеспечения балансировки нагрузки модель использует стратегию избыточных экспертов, которая динамически корректирует их распределение.
Эта архитектура обеспечивает эффективный вывод с высокой пропускной способностью, поддерживая как производительность, так и стабильность.
Оценка производительности
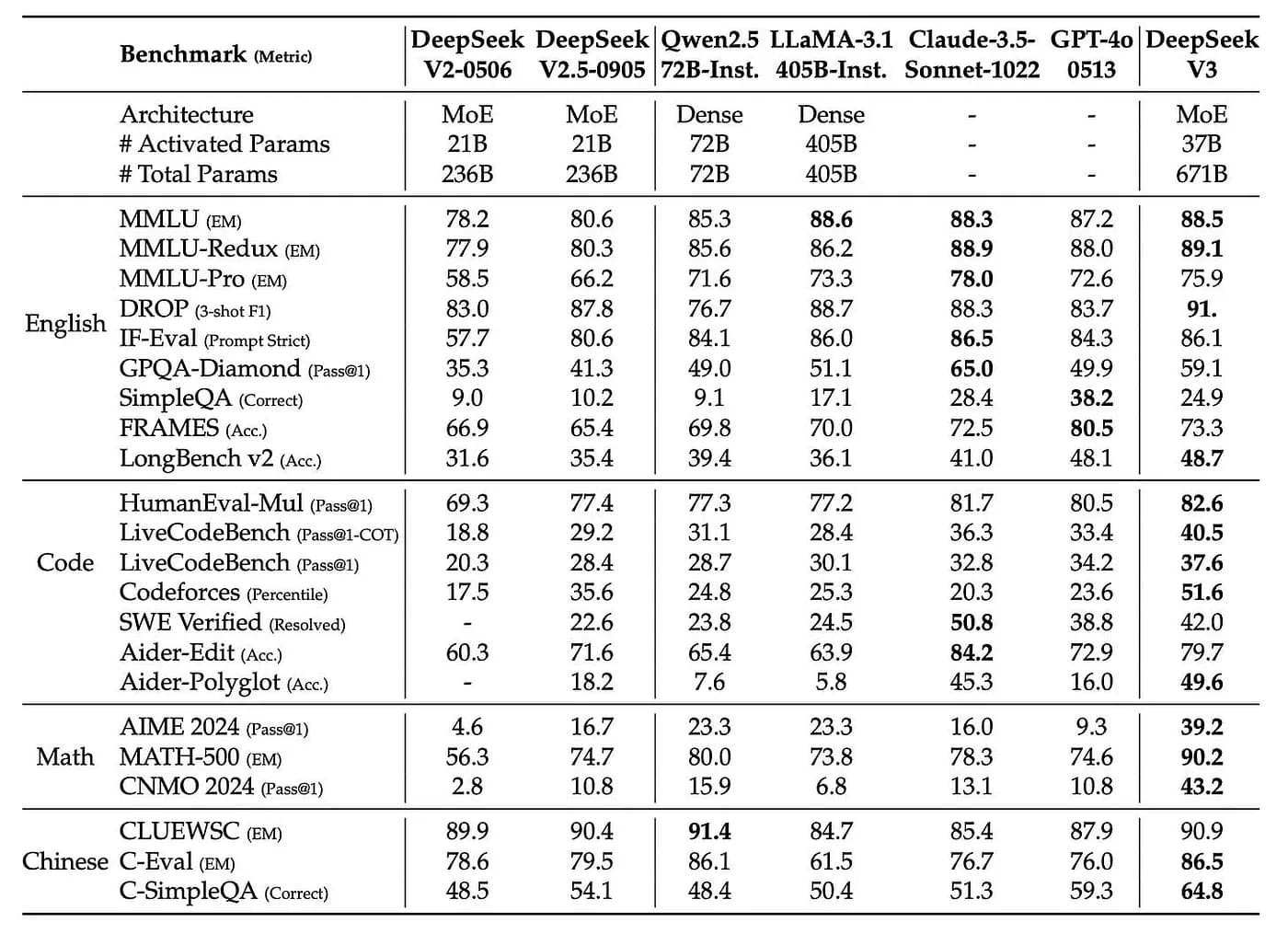
DeepSeek-V3 достигает передовых результатов среди моделей с открытым исходным кодом в различных тестах, с результатами, сопоставимыми с ведущими закрытыми моделями, такими как GPT-4.
- В области знаний DeepSeek-V3 превосходит все модели с открытым исходным кодом в тестах на знания, таких как MMLU и GPQA, и приближается к закрытым моделям, таким как GPT-4o и Claude-Sonnet-3.5.
- В математических рассуждениях и программировании DeepSeek-V3 превосходит других в математических тестах (MATH-500) и задачах программирования (например, LiveCodeBench), становясь ведущей моделью в этих областях.
- В многоязычных возможностях DeepSeek-V3 показывает сильные результаты в области китайских фактических знаний, превосходя даже GPT-4o и Claude-Sonnet-3.5.
В целом, DeepSeek-V3 является одной из самых передовых языковых моделей с открытым исходным кодом, с инновациями от архитектурного дизайна до обучения и развертывания.
Некоторыми мысли и опасения относительно DeepSeek-V3:
-
Аварийное восстановление в крупномасштабной распределенной архитектуре вывода: механизмы избыточных экспертов и динамической маршрутизации DeepSeek-V3 сфокусированы на балансировке нагрузки, а не на комплексной оптимизации аварийного восстановления. Например, хотя избыточные эксперты могут помочь распределить нагрузку, при отказе ранга (например, одновременном выходе из строя нескольких GPU) избыточных ресурсов может не хватить для покрытия всех отказавших задач.
-
Стабильность обучения: Хотя вычисления с низкой точностью FP8 значительно снижают затраты памяти и коммуникации, их более узкий динамический диапазон (особенно с форматом E4M3) может вносить некоторые ошибки во время обучения. Хотя методы поплиточной и поблочной квантизации помогают смягчить некоторые из этих проблем, у меня все еще есть сомнения относительно того, насколько этот подход к квантизации повлияет на стабильность обучения.
-
Качество обучающих данных: OpenAI инвестировала значительные человеческие и материальные ресурсы в разметку данных. В более поздних языковых моделях возможно, что часть обучающих данных может быть сгенерирована ChatGPT. Если это станет большой частью данных, это может привести к таким проблемам, как дисбаланс распределения данных, и выходные данные могут оказаться недостаточно глубокими или креативными.