От имитации к интеллекту. Будущее ИИ за обучением с подкреплением (RL)

Одна из самых красивых исследовательских работ за долгое время проясняет, почему индустрия ИИ стала настолько одержима парадигмой обучения с подкреплением (Reinforcement Learning, RL), которая создала самые мощные модели ИИ, известные человечеству.
Проще говоря, возможно, мы движемся в правильном направлении к настоящему искусственному интеллекту.
Звучит гиперболично, но возможно, что через несколько минут вы согласитесь. Опубликованная группой исследователей из США и Гонконга, эта работа показывает, как развиваются модели ИИ в процессе пост-обучения (улучшения в конкретных областях) и как выбор техники обучения имеет решающее значение.
Если вы хотите лучше понять нюансы обучения передовых моделей ИИ и почему это очень, очень захватывающее время в развитии ИИ, читайте дальше.
Что действительно означает обучение ИИ?
Существует два основных метода обучения моделей ИИ: имитация и исследование.
- Первый обучает модели ИИ, заставляя их имитировать данные (95% или более всех существующих ИИ были обучены именно так),
- а второй обучает модели, предоставляя им возможность найти неизвестный способ (по крайней мере, для модели) решения проблемы, всегда предполагая, что базовая модель, которая собирается исследовать, имеет выше случайную вероятность решения проблемы (иначе это просто угадывание, что означает, что обучение займет вечность).
А куда относятся большие языковые модели (Large Language Models) или генеративные модели ИИ в целом? Это смесь.
Они всегда начинают с имитационного обучения в масштабе, заставляя их имитировать триллионы слов данных. Это дает нам базовую модель. Однако это не та модель, которую вы используете, поскольку те, что выходят на рынок, всегда проходят техники пост-обучения.
Они также делятся на два типа:
- Контролируемая тонкая настройка (Supervised Fine-tuning, SFT): Техника имитационного обучения, где мы подготавливаем достаточно большой набор данных, который модель должна снова имитировать. Однако на этот раз набор данных имеет исключительно высокое качество и смещен в сторону способностей, таких как следование инструкциям, отказ от вредных запросов, пошаговое рассуждение (цепочка мыслей) и конкретные области, в которых лаборатория ИИ хочет убедиться, что модель хороша.
- Обучение с подкреплением (Reinforcement Learning): Это основанный на исследовании режим обучения методом проб и ошибок, где модель знает финальный ответ и должна найти к нему путь, как объяснялось ранее.
Хотя оба подхода звучат похоже, семантика здесь имеет значение. И понимание нюансов обоих парадигм — довольно продвинутое место в вашей кривой изучения ИИ.
Хотя обе техники могут использовать одни и те же проблемы для тестирования, подход — хотя и неправильно понимаемый даже многими исследователями — принципиально отличается.
- Первый буквально направляет модель от вопроса к решению, включая все промежуточные шаги.
- В качестве альтернативы, второй предоставляет модели правильное решение и... все, заставляя модель самостоятельно решать, как его достичь.
Один и тот же конечный результат, два совершенно разных способа его достижения.
Но подождите секунду, если SFT показывает модели точно, как решить проблему, зачем нам беспокоиться об использовании RL и других техник исследования, которые кажутся гораздо менее эффективными?
И ответ, суть сегодняшнего исследования, — это обобщение, или его явное отсутствие в одном из случаев.
Тонкая настройка (переобучение модели) всегда имеет свою цену: если вы интенсивно обучаете модель в новой области, вы рискуете потерять производительность в других областях.
Конечно, этого не должно происходить, если модель действительно «интеллектуальная».
Если модель действительно абстрагирует паттерны, а не запоминает решения, хорошие математические основы должны переноситься на другие науки, поскольку математика — основа всех STEM-областей.
Как отвечает Питер Салливан в фильме «Предел риска» (Margin Call), когда его спрашивают, почему ракетный ученый оказался в отделе управления рисками крупного инвестиционного банка:
«Ну, это все числа, правда. Просто меняешь то, что складываешь. И, откровенно говоря, деньги здесь значительно привлекательнее».
Проще говоря, модель, которая действительно понимает математику, должна быть способна обобщать и применять свои знания к физике или химии, или, по крайней мере, быть способной применять математические знания к этим областям при их изучении, а не переизучать эти основы.
И вот здесь все становится мутным и создает почву для одной из самых важных вещей, которые вы можете узнать об обучении ИИ:
Основной вывод исследования заключается в том, что имитационное обучение, хотя и более удобное, убивает обобщение; оно убивает интеллект, понимаемый как форма адаптации «известных известных» к неизвестному.
И это имеет решающее значение.
Обобщение — это интеллект
Хотя имитационное обучение долгое время было основным режимом обучения, даже на передовом уровне, это исследование предоставляет конкретные доказательства того, что RL хорошо обобщается на разные области, предлагая новое объяснение того, почему лаборатории ИИ так заинтересованы в этом типе обучения.
Чтобы доказать это, они провели следующий тест:
Используя одну и ту же базовую модель и набор данных для тонкой настройки, обеспечивая, что техника обучения (имитация против RL) является единственным различием и, таким образом, гарантируя, что если мы наблюдаем различия, это связано с методом тонкой настройки, они обучили две разные модели, чтобы увидеть, смогут ли они наблюдать различия в том, как модели затем будут работать в областях, для которых они не были обучены явно (т.е., обучение математике, тестирование в науках или написании эссе).
И результаты были ясны как день. После оценки математически настроенных моделей на бенчмарках, связанных с другими математическими областями,
- RL-модель улучшила производительность во всех областях, включая те, которые, по-видимому, не связаны с математикой.
- В отличие от этого, SFT-модель показала смешанные результаты. Хотя она показала умеренное улучшение в связанных с математикой областях (науки), ее производительность серьезно снизилась в областях, не связанных с рассуждениями.
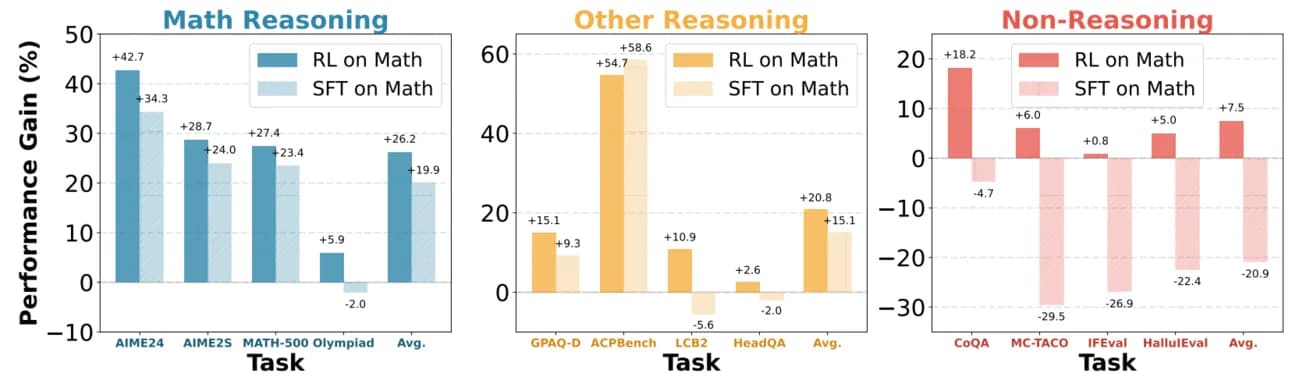
Следует сказать, что они не тестировали, были ли различия статистически значимыми, хотя они очень убедительны.
В двух словах, одна и та же модель, обученная на одном и том же наборе данных, демонстрирует улучшенные способности к обобщению при тонкой настройке с использованием техник, основанных на исследовании. В отличие от этого, она регрессирует в нематематических областях при обучении математике с использованием имитационного обучения.
Поэтому мы можем заключить, что:
- Имитационное обучение позволяет модели механически имитировать набор данных, потенциально забывая релевантную информацию в процессе, если это необходимо; ей это не нужно, поскольку процесс решения выложен для нее, так зачем беспокоиться об использовании предыдущих знаний? Зачем думать нестандартно, если ответ прямо перед вами?
- С другой стороны, модель, основанная на исследовании, поскольку она вынуждена найти решение проблемы, гораздо более вероятно основывает свое решение на известных основах (вещах, которые она знает).
Интуитивно вы можете рассмотреть это с точки зрения человеческого обучения. Представьте себя изучающим двумя методами. В первом случае вам дают решение, поэтому вам не нужно ничего вспоминать, просто имитировать. Во втором случае вам не дают процесс решения, поэтому вам лучше использовать ваши «известные известные» для решения проблемы.
В некотором смысле, один — это ленивый способ обучения, требующий низких когнитивных усилий, просто механическая имитация, в то время как другой требует настоящего «интеллекта», который есть не что иное, как применение изученных абстракций к новым данным.
Как однажды сказал Жан Пиаже: «Интеллект — это то, что вы используете, когда не знаете, что делать». При имитационном обучении ответ просто есть, поэтому моделям не нужно быть интеллектуальными, им просто нужно быть хорошими запоминающими устройствами.
Двигаясь дальше, они дополнительно доказали тезис, используя PCA (анализ главных компонент), технику уменьшения размерности, которая показывает два измерения наибольшей дисперсии в скрытых активациях модели.
Они анализируют внутренние структуры модели, чтобы увидеть, сильно ли они изменились после тонкой настройки. Если внутренняя структура модели значительно варьируется, мы предполагаем, что техника не эффективно способствует обобщению, а скорее слишком сильно направляет модель в эту область, очень изысканный способ сказать «модель просто запоминает данные»; она не находит новые способы использования того, что знает, для адаптации к новой области, она изучает все «с нуля» снова и забывает предыдущие знания в процессе.
Наоборот, если внутренние структуры остаются «похожими», несмотря на улучшение выходных данных модели, это предполагает, что понимание моделью математики и наук в целом не сильно изменилось, несмотря на то, что модель стала лучше в математике, указывая на то, что она просто изучает новые важные вещи и сохраняет большинство правильных убеждений модели нетронутыми, адаптируясь только тогда, когда изученных основ недостаточно для решения проблемы.
Как вы можете видеть ниже, модель в первых двух рядах, SFT-модель (модель, обученная имитацией), показывает очень разную структуру паттернов, предполагая, что модель сильно изменилась с обучением SFT.
Напротив, RL-модель (третий ряд) все еще показывает внутреннюю структуру, очень похожую на базовую модель (несмотря на улучшенную производительность), доказывая, что вы можете обучать модели быть лучше в новой области, не изменяя слишком сильно базовую структуру модели, подобно тому, как вам не нужно переопределять все ваши убеждения о математике всякий раз, когда вы изучаете новые области, такие как физика (2+2 = 4 в обеих областях, так зачем беспокоиться о переизучении того, что вы уже считаете истинным?).
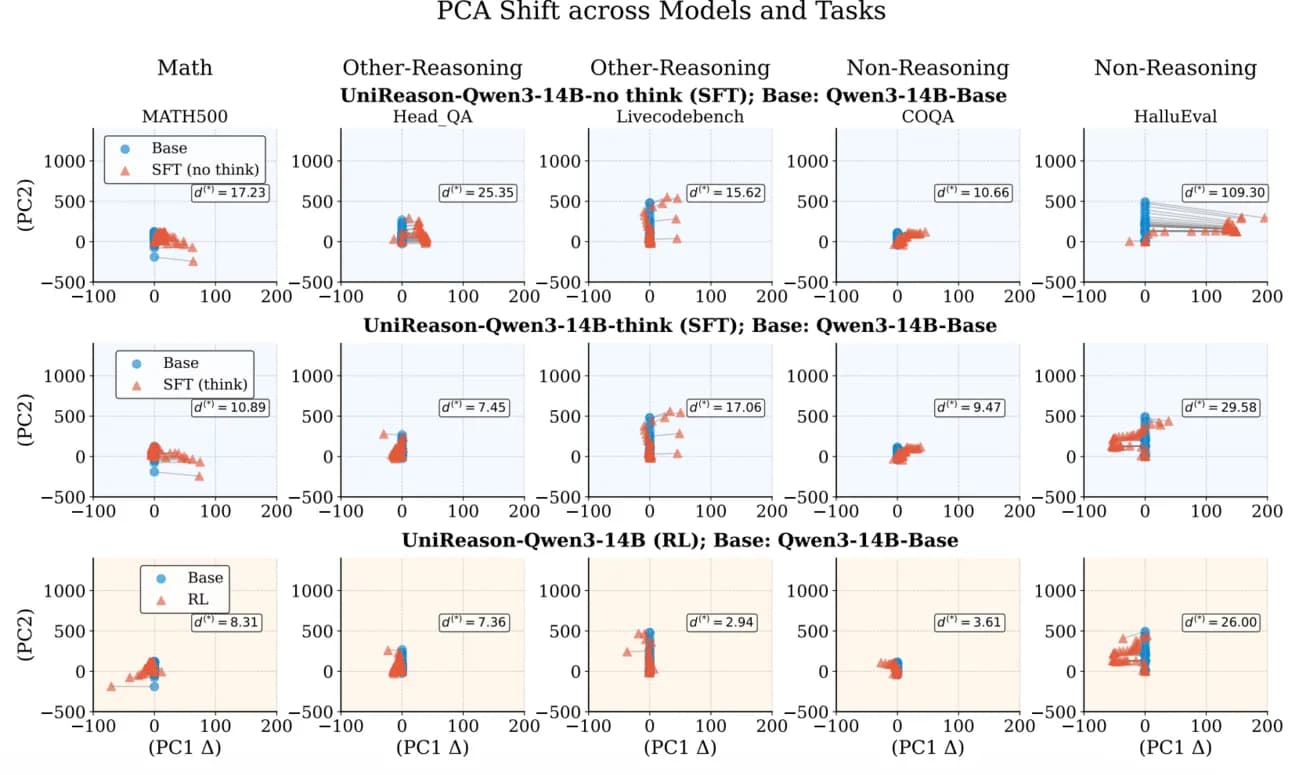
Подводя итог, ключевые абстракции, которые являются общими для всех наук, не подвергаются сомнению новой математикой; вы просто адаптируете свой мозг к новым знаниям, не изменяя то, что вы уже знаете как работающее.
Короче говоря, обобщение — это интеллект, и новый режим обучения, доминирующий в сфере ИИ в наши дни (как иллюстрирует Grok 4), обучение с подкреплением, является многообещающим способом развития настоящего интеллекта в машинах.