DeepSeek-V3: Китайская LLM-модель с открытым исходным кодом обошла GPT-4 и Claude 3.5 в тестах по математике и программированию

В последних числах декабря 2024 года, китайская компания DeepSeek выпустила свою новую модель с открытым исходным кодом DeepSeek V3, которая превзошла все основные нейросети, будь то Claude 3.5 Sonnet, GPT-4o, Qwen2.5 Coder и другие. Производительность модели выглядит впечатляюще, и мы можем с уверенностью сказать, что
DeepSeek-V3 — лучшая модель с открытым исходным кодом, выпущенная на данный момент
Одна из крупнейших LLM-моделей
DeepSeek-V3 может похвастаться внушительным размером в 685 миллиардов параметров, что делает её одной из крупнейших моделей в области ИИ. Такое обширное количество параметров обеспечивает более тонкое понимание и генерацию текста.
Высокая скорость
60 токенов/секунду (в 3 раза быстрее, чем DeepSeek V2)
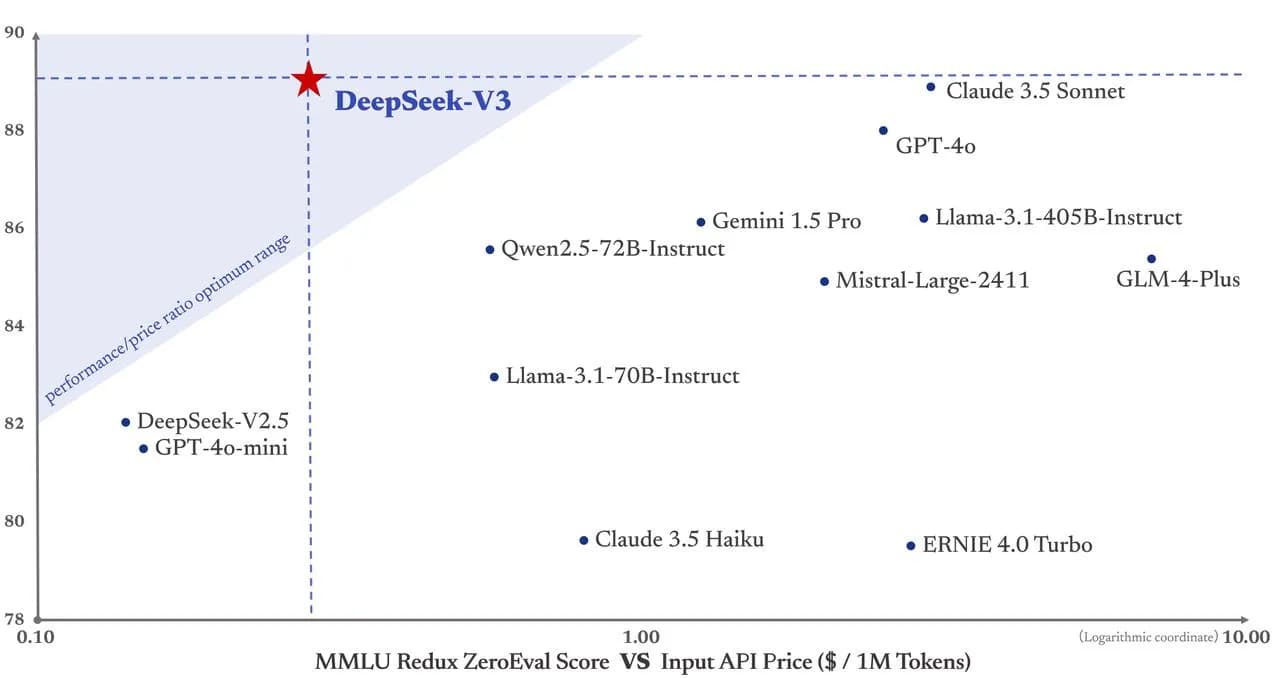
График подчеркивает превосходство DeepSeek-V3 на основе соотношения производительности к цене и точности (показатель MMLU Redux ZeroEval). Вот почему она лучшая:
- Высокая точность: DeepSeek-V3 набирает около 90 баллов, превосходя большинство моделей с открытым исходным кодом и даже конкурируя с проприетарными моделями, такими как Claude 3.5 и GPT-4.
- Оптимальная стоимость: Она попадает в оптимальный диапазон производительности/цены, что делает её высокоэффективной с точки зрения стоимости API за миллион токенов по сравнению с другими высокопроизводительными моделями.
- Сбалансированная производительность и доступность: В отличие от дорогих проприетарных моделей, DeepSeek-V3 предлагает конкурентоспособную производительность, оставаясь при этом открытой, что обеспечивает доступность и гибкость.
Ключевые особенности DeepSeek-V3:
Размер модели и эффективность:
- 671 млрд общих параметров, из которых 37 млрд активируются на токен
- Использует архитектуру Mixture-of-Experts (MoE) для большей эффективности
Mixture-of-Experts (MoE) LLM — это тип модели ИИ, использующий множество специализированных «экспертов» (меньших подмоделей). Для каждого входящего элемента активируются только некоторые из этих экспертов, что делает модель более быстрой и эффективной. Это похоже на группу специалистов, где консультируются только с нужными экспертами для каждой задачи, вместо того чтобы спрашивать всех.
Архитектурные инновации:
- Реализует архитектуры Multi-head Latent Attention (MLA) и DeepSeekMoE, основываясь на достижениях DeepSeek-V2
- Внедряет стратегию балансировки нагрузки без вспомогательных потерь
- Применяет цель обучения с предсказанием множественных токенов для повышения производительности
Обучающий датасет:
- Предварительно обучен на 14,8 триллионах высококачественных токенов, обеспечивающих разнообразные и богатые данные
Процесс обучения:
- Включает этапы Supervised Fine-Tuning (контролируемой тонкой настройки) и Reinforcement Learning (обучения с подкреплением)
- Требует только 2,788 млн часов работы GPU H800, что делает его экономически эффективным
- Стабильный процесс обучения без необратимых пиков потерь или откатов
Производительность и метрики
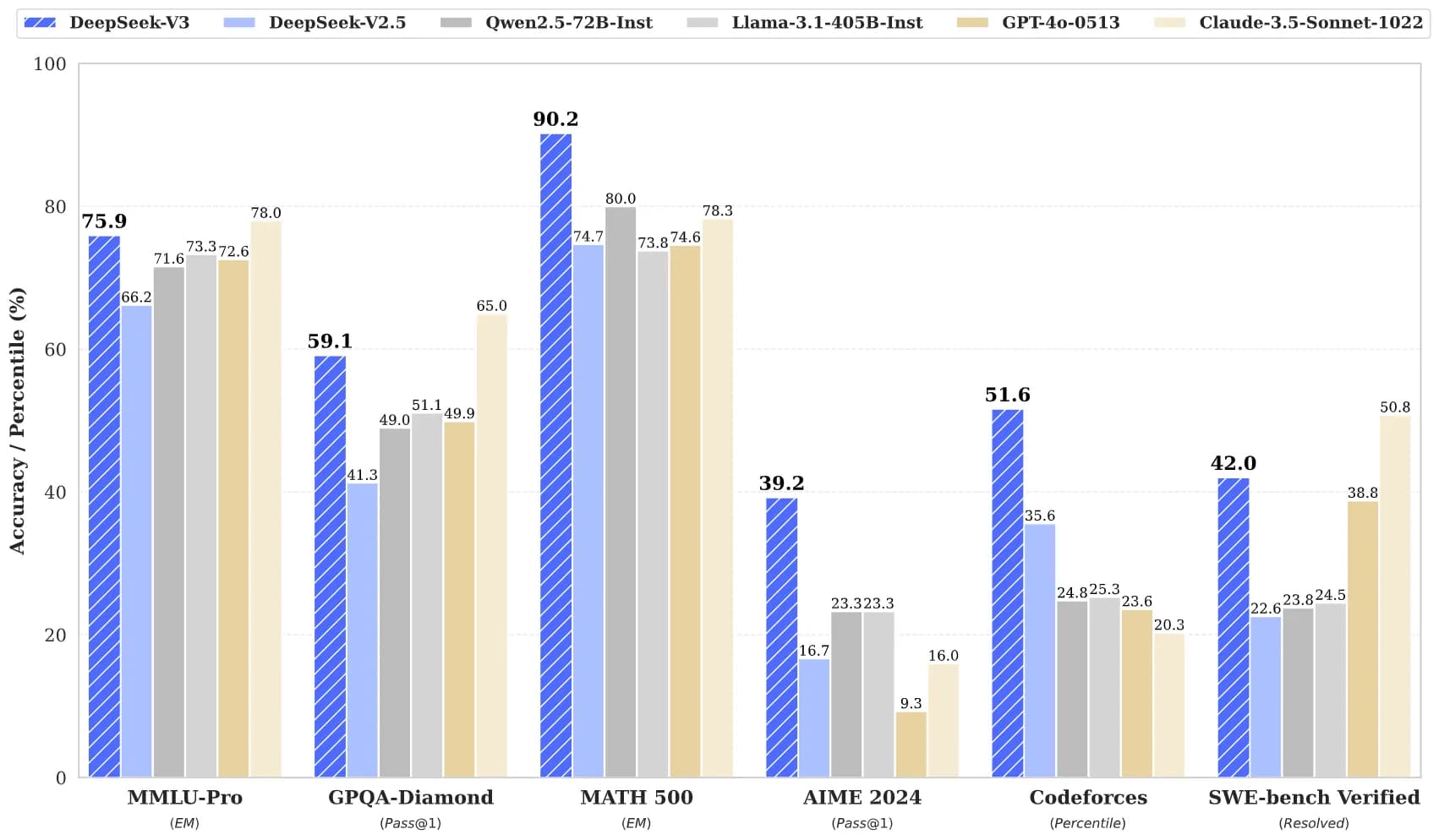
Подводя итоги результатов:
MMLU-Pro (Понимание знаний):
- DeepSeek-V3: 75,9% (второе место)
- Немного отстает от GPT-4 (78%), превосходя все остальные модели
GPQA-Diamond (Сложные вопросы и ответы):
- DeepSeek-V3: 59,1%
- Значительно опережает GPT-4 (49,9%) и другие. Только Claude показывает лучший результат
MATH 500 (Математические рассуждения):
- DeepSeek-V3: 90,2% (лучший результат)
- Значительно превосходит GPT-4 и другие модели
AIME 2024 (Продвинутые математические рассуждения):
- DeepSeek-V3: 39,2% (лучший результат)
- Опережает GPT-4 и другие более чем на 23%
Codeforces (Решение задач программирования):
- DeepSeek-V3: 51,6% (лучший результат)
- Значительно превосходит GPT-4 и другие модели
SWE-bench Verified (Разработка программного обеспечения):
- DeepSeek-V3: 42% (второе место)
- Уступает Claude Sonnet (50,8%), но опережает большинство других моделей
Как использовать DeepSeek-V3?
Все модели находятся в открытом доступе и доступны через HuggingFace.
Если вы просто хотите пообщаться, модель бесплатно размещена на официальном сайте deepseek: https://www.deepseek.com