Приложение для преобразования речи в текст на Next.js 14 и OpenAI API

Оглавление:
- Инициализация проекта
- Инициализация Next.js
- Установка необходимых зависимостей, таких как openai
- Создание хука useRecordVoice
- Разработка хука для записи голоса
- Использование API MediaRecorder
- Создание компонента кнопки
- Создание компонента кнопки для управления записью голоса
- Проверка функциональности
- Запуск проекта и проверка основных функций
- Настройка API распознавания речи
- Создание API-эндпоинта для обработки аудиоданных и взаимодействия с API OpenAI
- Дополнительные функции и улучшения
- Разработка вспомогательных функций для аудио и преобразования в base64
- Реализация дополнительных функций для получения текстового вывода
Шаг 1. Инициализация проекта
Для начала инициализируйте проект Next.js и установите необходимые зависимости, включая openai.
Инициализация проекта Next.js
npx create-next-app my-voice-app
Установка необходимых зависимостей: openai v4, dotenv
npm install openai dotenv
Шаг 2. Создание хука useRecordVoice
Разработка хука для записи голоса с использованием API MediaRecorder.
import { useEffect, useState, useRef } from "react";
export const useRecordVoice = () => {
// Состояние для хранения экземпляра MediaRecorder
const [mediaRecorder, setMediaRecorder] = useState(null);
// Состояние для отслеживания, идет ли запись в данный момент
const [recording, setRecording] = useState(false);
// Ссылка для хранения аудио-фрагментов во время записи
const chunks = useRef([]);
// Функция для начала записи
const startRecording = () => {
if (mediaRecorder) {
mediaRecorder.start();
setRecording(true);
}
};
// Функция для остановки записи
const stopRecording = () => {
if (mediaRecorder) {
mediaRecorder.stop();
setRecording(false);
}
};
// Функция для инициализации MediaRecorder
const initialMediaRecorder = (stream) => {
const mediaRecorder = new MediaRecorder(stream);
// Обработчик события при начале записи
mediaRecorder.onstart = () => {
chunks.current = []; // Сброс массива фрагментов
};
// Обработчик события при доступности данных во время записи
mediaRecorder.ondataavailable = (ev) => {
chunks.current.push(ev.data); // Сохранение фрагментов данных
};
// Обработчик события при остановке записи
mediaRecorder.onstop = () => {
// Создание Blob из накопленных аудио-фрагментов в формате WAV
const audioBlob = new Blob(chunks.current, { type: "audio/wav" });
console.log(audioBlob, 'audioBlob');
// Вы можете выполнить какие-либо действия с audioBlob, например, отправить его на сервер или дальнейшую обработку
};
setMediaRecorder(mediaRecorder);
};
useEffect(() => {
if (typeof window !== "undefined") {
navigator.mediaDevices
.getUserMedia({ audio: true })
.then(initialMediaRecorder);
}
}, []);
return { recording, startRecording, stopRecording };
};
Шаг 3. Создание компонента Button
Разработка компонента кнопки для начала и остановки записи голоса.
import { useRecordVoice } from "@/hooks/useRecordVoice";
import { IconMicrophone } from "@/app/components/IconMicrophone";
const Microphone = () => {
const { startRecording, stopRecording } = useRecordVoice();
return (
// Кнопка для начала и остановки записи голоса
<button
onMouseDown={startRecording} // Начать запись при нажатии кнопки мыши
onMouseUp={stopRecording} // Остановить запись при отпускании кнопки мыши
onTouchStart={startRecording} // Начать запись при начале касания на сенсорном устройстве
onTouchEnd={stopRecording} // Остановить запись при окончании касания на сенсорном устройстве
className="border-none bg-transparent w-10"
>
{/* Компонент иконки микрофона */}
<IconMicrophone />
</button>
);
};
export { Microphone };
Шаг 4. Проверка функциональности
Запустите проект и проверьте основную функциональность.
npm run dev
Откройте http://localhost:3000/ в вашем браузере и убедитесь, что появляется запрос на разрешение доступа к микрофону.
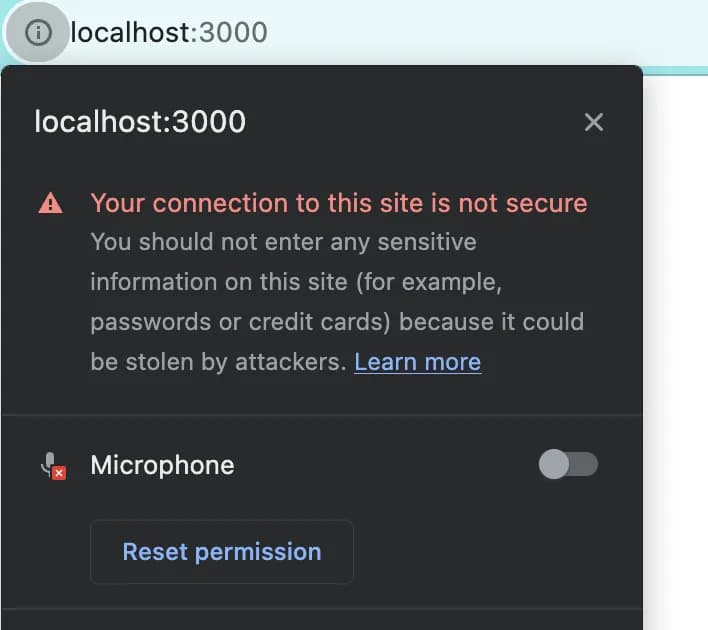
После этого на вкладке браузера должен загореться индикатор микрофона, означающий, что вы все сделали правильно.

Далее, нажмите и удерживайте кнопку микрофона и скажите что-нибудь, после чего в консоли вы должны увидеть что-то подобное, только другого размера.

5. Настройка API распознавания речи
Создайте конечную точку API для обработки аудиоданных и взаимодействия с API OpenAI.
В папке src/app/api/speechToText/route.js создадим API speechToText.
import { NextResponse } from "next/server";
import fs from "fs";
import * as dotenv from "dotenv";
import OpenAI from "openai";
import { env } from "../../config/env";
dotenv.config();
const openai = new OpenAI({
apiKey: env.OPENAI_API_KEY,
});
export async function POST(req) {
const body = await req.json();
const base64Audio = body.audio;
// Преобразование base64 аудиоданных в Buffer
const audio = Buffer.from(base64Audio, "base64");
// Определение пути к файлу для хранения временного WAV-файла
const filePath = "tmp/input.wav";
try {
// Синхронная запись аудиоданных во временный WAV-файл
fs.writeFileSync(filePath, audio);
// Создание потока чтения из временного WAV-файла
const readStream = fs.createReadStream(filePath);
const data = await openai.audio.transcriptions.create({
file: readStream,
model: "whisper-1"
});
// Удаление временного файла после успешной обработки
fs.unlinkSync(filePath);
return NextResponse.json(data);
} catch (error) {
console.error("Ошибка обработки аудио:", error);
return NextResponse.error();
}
}
Вкратце, здесь мы создаем файл, в который записываем base64Audio, затем читаем его и после успешного запроса удаляем файл.
Также убедитесь, что вы создали папку tmp на том же уровне, что и src, и добавили .gitignore, чтобы вы могли фиксировать и отправлять эту папку.
6. Дополнительные функции и улучшения
Добавим вспомогательные функции для преобразования аудио и base64, а также улучшим функциональность.
blobToBase64
// callback - где мы хотим получить результат
const blobToBase64 = (blob, callback) => {
const reader = new FileReader();
reader.onload = function () {
const base64data = reader?.result?.split(",")[1];
callback(base64data);
};
reader.readAsDataURL(blob);
};
export { blobToBase64 };
createMediaStream
// Функция для вычисления пикового уровня из данных анализатора
const getPeakLevel = (analyzer) => {
// Создание Uint8Array для хранения аудиоданных
const array = new Uint8Array(analyzer.fftSize);
// Получение данных временной области из анализатора и сохранение их в массиве
analyzer.getByteTimeDomainData(array);
// Вычисление пикового уровня путем нахождения максимального абсолютного отклонения от 127
return (
array.reduce((max, current) => Math.max(max, Math.abs(current - 127)), 0) /
128
);
};
const createMediaStream = (stream, isRecording, callback) => {
// Создание нового AudioContext
const context = new AudioContext();
// Создание узла источника медиа-потока из входного потока
const source = context.createMediaStreamSource(stream);
// Создание узла анализатора для анализа аудио
const analyzer = context.createAnalyser();
// Подключение узла источника к узлу анализатора
source.connect(analyzer);
// Функция для непрерывного анализа аудиоданных и вызова обратного вызова
const tick = () => {
// Вычисление пикового уровня с помощью функции getPeakLevel
const peak = getPeakLevel(analyzer);
if (isRecording) {
callback(peak);
// Запрос следующего кадра анимации для непрерывного анализа
requestAnimationFrame(tick);
}
};
// Запуск цикла непрерывного анализа
tick();
};
export { createMediaStream };
Вы можете узнать больше о встроенном методе JavaScript requestAnimationFrame здесь.
Теперь используем наши вспомогательные функции и speechToText API в useRecordVoice.
"use client";
import { useEffect, useState, useRef } from "react";
import { blobToBase64 } from "@/utils/blobToBase64";
import { createMediaStream } from "@/utils/createMediaStream";
export const useRecordVoice = () => {
const [text, setText] = useState("");
const [mediaRecorder, setMediaRecorder] = useState(null);
const [recording, setRecording] = useState(false);
const isRecording = useRef(false);
const chunks = useRef([]);
const startRecording = () => {
if (mediaRecorder) {
isRecording.current = true;
mediaRecorder.start();
setRecording(true);
}
};
const stopRecording = () => {
if (mediaRecorder) {
isRecording.current = false;
mediaRecorder.stop();
setRecording(false);
}
};
const getText = async (base64data) => {
try {
const response = await fetch("/api/speechToText", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
audio: base64data,
}),
}).then((res) => res.json());
const { text } = response;
setText(text);
} catch (error) {
console.log(error);
}
};
const initialMediaRecorder = (stream) => {
const mediaRecorder = new MediaRecorder(stream);
mediaRecorder.onstart = () => {
createMediaStream(stream, isRecording.current, () => {});
chunks.current = [];
};
mediaRecorder.ondataavailable = (ev) => {
chunks.current.push(ev.data);
};
mediaRecorder.onstop = () => {
const audioBlob = new Blob(chunks.current, { type: "audio/wav" });
blobToBase64(audioBlob, getText);
};
setMediaRecorder(mediaRecorder);
};
useEffect(() => {
if (typeof window !== "undefined") {
navigator.mediaDevices
.getUserMedia({ audio: true })
.then(initialMediaRecorder);
}
}, []);
return { recording, startRecording, stopRecording, text };
};
После этого перейдите в компонент Microphone и добавьте вывод нашего текста.
const Microphone = () => {
const { startRecording, stopRecording, text } = useRecordVoice();
return (
<div className="flex flex-col justify-center items-center">
<button
onMouseDown={startRecording}
onMouseUp={stopRecording}
onTouchStart={startRecording}
onTouchEnd={stopRecording}
className="border-none bg-transparent w-10"
>
<IconMicrophone />
</button>
<p>{text}</p>
</div>
);
};
export { Microphone };
Сохраните изменения и перезапустите сервер.
Затем перейдите на http://localhost:3000/ и выполните следующие действия:
- Нажмите кнопку микрофона.
- Скажите: "Hello world".

Все готово! Теперь в вашем приложении Next.js есть полностью функциональный голосовой ввод.