Насколько ИИ близок к человеческому разуму? Анализ современных достижений и ограничений

«Они думают, что интеллект заключается в том, чтобы замечать значимые вещи (обнаруживать паттерны); в сложном мире интеллект состоит в том, чтобы игнорировать несущественное (избегать ложных паттернов)» — Нассим Николас Талеб
Когда OpenAI представила o1, компания заявила, что их новейшая большая языковая модель (LLM) демонстрирует новый уровень возможностей ИИ. Сегодня ажиотаж в значительной степени утих, а возможности этой модели были воспроизведены в открытом исходном коде. На короткий момент возникло ощущение, когда казалось, что модель почти достигла человеческих возможностей. Помимо маркетинга, o1 снова спровоцировала дискуссию о том, насколько продвинуты LLM на самом деле, насколько хорошо они отражают человеческие способности и что требуется для создания искусственного интеллекта с такими же когнитивными возможностями, как у нас.
В этой статье мы попытаемся ответить на следующие вопросы:
- Каковы текущие ограничения ИИ?
- Является ли LLM тем, что приведет нас к ИИ человеческого уровня?
- Что нам нужно для AGI?
Искусственный интеллект трансформирует наш мир, формируя то, как мы живем и работаем. Понимание того, как он работает и каковы его последствия, никогда не было более важным. Если вы ищете простые, понятные объяснения сложных тем, связанных с ИИ, вы находитесь в нужном месте.
Пределы Бога
Революция LLM привела к предположениям, что мы близки к разработке искусственного общего интеллекта (AGI). Появление ChatGPT стало моментом эйфории, когда можно было общаться с чат-ботом, обладающим невиданными ранее возможностями, почти как с другим человеком. Затем восторг угас. Однако до 2022 года широкая общественность никогда не задавалась вопросом: находится ли искусственный интеллект на когнитивном уровне человека?
Это связано с тем, что предыдущие модели обладали сверхчеловеческими возможностями, но только для специализированных задач. Например, AlphaGo смогла с относительной легкостью победить профессионального игрока в го, но никто не думал, что умение играть в го делает нас людьми. Однако в 2022 году DALL-E и ChatGPT продемонстрировали способности, которые мы обычно связываем исключительно с людьми: создание искусства и способность писать.
LLM не только хорошо пишут, но и демонстрируют такой же широкий и гибкий спектр навыков, как у нас. За короткое время они показали, что могут сдавать экзамены, которые обычно предназначались для людей. Это привело к эффекту «зловещей долины» при общении с ними и к страху, что они вскоре могут заменить нас в нашей работе.
Но действительно ли LLM обладают когнитивными способностями, сходными или превосходящими человеческие?
Рассуждение и творчество — это две способности, которые обычно приписываются только людям. Обе эти способности трудно определить (и сложно найти однозначное определение и способ их измерения). Недавние исследования исключают, что LLM действительно способна к рассуждению. Если кратко, LLM использует свою гигантскую память для поиска паттернов, чтобы ответить на вопрос. Если она не может найти паттерны, она не способна решить проблему.
Кроме того, недавние исследования показывают, что LLM использует набор эвристик для решения математических вычислений. Другими словами, она использует набор правил, чтобы иметь возможность ответить на большое количество случаев. Этого обычно достаточно для ответа на большинство задач. LLM либо видела похожие паттерны в своем огромном обучающем наборе, либо может использовать одну из эвристик. Это не означает реального рассуждения.
Творчество в написании текстов недавно было поставлено под сомнение. До сих пор мы не могли сопоставить сгенерированный LLM текст с тем, что есть в Интернете. Это затрудняет оценку того, творческие ли LLM или нет. Новые методы позволяют нам провести этот анализ. Исслеждование четко показывают, что LLM не творческая — это просто текст, выученный во время обучения и воспроизведенный по запросу. При честном сравнении мы видим, что люди намного более креативны, чем LLM. По их мнению, сгенерированный текст, который кажется оригинальным, происходит из частных данных, использованных при обучении, которые мы не можем проанализировать. Кроме того, будучи «стохастическим попугаем», произведенный текст не точно такой же, а с некоторыми незначительными вариациями.

Эти результаты четко показывают, что LLM не способны ни к рассуждению, ни к творчеству. LLM впечатляют способностью находить информацию в огромном корпусе предварительного обучения и отвечать на вопросы пользователя, используя эти знания. Однако LLM не способны использовать эти знания, рекомбинировать их или создавать что-то новое.
Приведет ли LLM нас к AGI?
Когда в 2020 году был опубликован закон масштабирования, многие исследователи увидели в нем и чудо, и заповедь. Увеличивая количество параметров, текста и вычислений, потери можно было линейно уменьшать и прогнозировать. С этого момента путь был намечен, и масштабирование моделей стало религией. Вторым чудом стали эмерджентные свойства. Для многих это означало, что нам просто нужно масштабировать модель. Рассуждение и творчество, короче говоря, должны были появиться сами собой на каком-то этапе масштабирования.
Вера в закон масштабирования начала давать трещину в прошлом году. Во-первых, эмерджентные свойства могут быть не реальным явлением, а ошибкой измерения. Во-вторых, модели не масштабируются так хорошо, как предсказывалось (или, по крайней мере, LLM не настолько мощные, как предсказывал закон масштабирования). Одна поправка к догме заключалась в том, что существует не один закон масштабирования, а как минимум три. По мнению некоторых исследователей, нужно масштабировать предварительное обучение, пост-обучение (выравнивание, тонкая настройка или любой другой пост-процесс) и последний закон масштабирования: время вывода.
Сэм Альтман прежде горячо защищал гонку параметров (в конце концов, этот закон масштабирования был продуктом OpenAI), но теперь он, похоже, не так убежден:
«Когда мы начинали, основными убеждениями были, что глубокое обучение работает и улучшается с масштабом... предсказуемо... Вера религиозного уровня ... заключалась в том, что это не должно останавливаться... Затем мы получили результаты масштабирования... В какой-то момент нужно просто посмотреть на законы масштабирования и сказать, что мы будем продолжать это делать... Происходило что-то действительно фундаментальное. Мы открыли новую клетку в периодической таблице.»
Проблема в том, что закон масштабирования не является физическим законом (как бы его ни выдавали за таковой), а общим рецептом, который гласит: в большинстве случаев большее количество параметров и больше обучения приведут к лучшим результатам (меньшим потерям). Потери не являются показателем интеллекта, и экстраполировать от потерь концепцию интеллекта неверно.
Кроме того, новый закон масштабирования времени вывода ненадежен. Производительность улучшается с увеличением количества шагов, но после примерно 20 шагов начинает быстро ухудшаться. Кроме того, ChatGPT-4 o1 работает лучше, чем 4o только в нескольких случаях, показывая, что это увеличенное время обдумывания полезно для узких случаев (где можно создать надежные синтетические данные), а не для открытых задач.
Другим элементом беспокойства является то, что производительность LLM больше не улучшается экспоненциально. Илья Суцкевер заявил, что они подходят к плато и что «2010-е были эпохой масштабирования, теперь мы снова вернулись в эпоху чудес и открытий».
Это, однако, было предсказуемо. Даже если бы мы могли построить бесконечно большую модель, у нас нет достаточного количества качественного текста для ее обучения:
«Мы обнаружили, что общий эффективный запас общедоступных текстовых данных, созданных человеком, составляет порядка 300 триллионов токенов, с 90% доверительным интервалом от 100T до 1000T. Эта оценка включает только данные, достаточно высокого качества для использования в обучении, и учитывает возможность обучения моделей в течение нескольких эпох.»
Проблема в том, что модель учится только на текстах, и если нет качественных текстов, ее нельзя обучить. Качество важнее, чем просто сбор всех возможных текстов. Фактически, обучение на синтетических данных является своего рода «дистилляцией знаний» и может привести к коллапсу модели. Альтман утверждает, что Orion (который можно считать GPT-5) работает лучше предыдущих моделей, но не настолько, насколько надеялись (например, ничего сопоставимого с тем, что мы видели между GPT-3 и GPT-4).
LLM не приведут магическим образом к AGI просто путем их масштабирования, это теперь хорошо установлено. Трансформер имеет ограничения, это исключительная архитектура, но имеет ограничения в обобщении. Мы просто достигаем пределов технологии, которая была разработана для лучшего перевода и, к счастью, оказалась гораздо более гибкой, чем ожидалось.
Как достичь AGI?
«С продвинутой моделью мира ИИ мог бы развить личное понимание любого сценария, в котором он оказывается, и начать рассуждать о возможных решениях.»
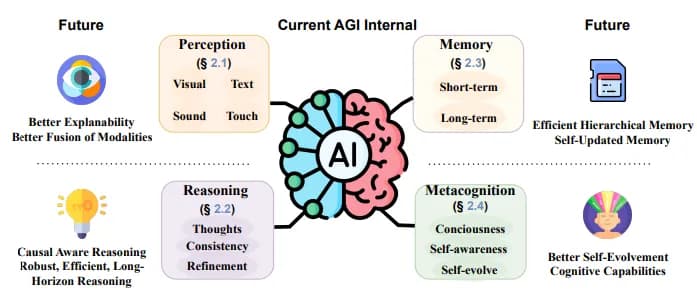
Вдохновением для создания AGI является человеческий мозг. В основном некоторые аспекты человеческого познания все еще ускользают от понимания. Для некоторых одним из необходимых элементов для AGI является развитие «модели мира». Другими словами, человеческий мозг учится представлению внешней среды. Это представление используется для воображения возможных действий или последствий действий. Эта модель также использовалась бы для обобщения задач, которые мы изучили в одной области, и применения их к другой.
Некоторые исследователи утверждают, что LLM во время обучения сформировали рудиментарную модель мира. Например, в одной статье авторы показывают, что LLM во время обучения формируют пространственные (и временные) словесные модели, которые затем можно извлечь и изучить.
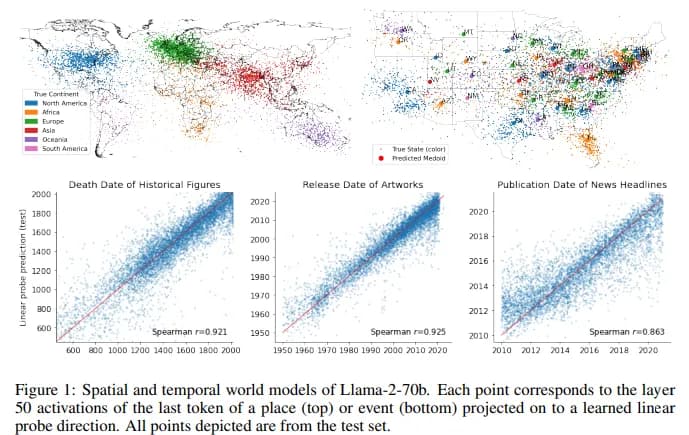
Есть и другие элементы, указывающие на появление внутреннего представления мира. Внутренние представления моделей о словах цвета похожи на факты о человеческом восприятии цвета, способность делать выводы о убеждениях автора документа, внутреннее представление пространственной компоновки обстановки истории и тот факт, что они проходят различные тесты на основе здравого смысла.
Другие исследователи показывают, что модели, обученные на записях игр, таких как шахматы или реверси, учатся представлению мира, которое затем можно использовать для прогнозирования ходов. Эти ходы были бы законными, и модель использовала бы это представление для оценки силы своего противника.
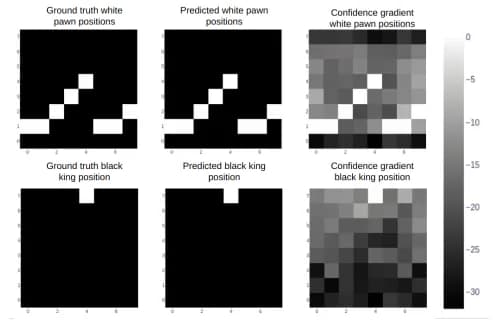
«Хотя такие пространственно-временные представления сами по себе не составляют динамическую причинную модель мира, наличие согласованных многомасштабных представлений пространства и времени являются базовыми ингредиентами, необходимыми в более комплексной модели.»
Для нескольких авторов эти элементы означают, что хотя эта модель мира рудиментарна, LLM уже показывают первые ингредиенты, и, таким образом, будущие инновации (или масштабирование) позволили бы развиться внутренней модели мира и совершить эволюционный скачок в познании.
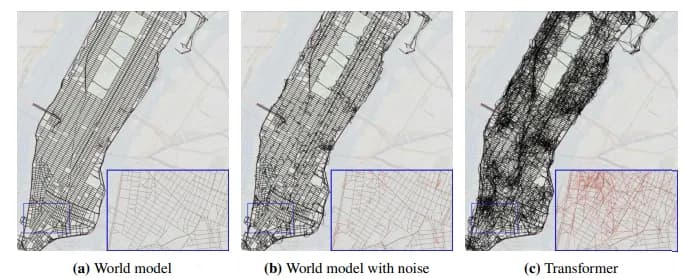
Однако консенсуса нет. По мнению других исследователей: даже если эта модель мира присутствует, она не используется ни для симуляций, ни для изучения причинно-следственных связей. Более того, эта модель ненадежна и является лишь приближением. В недавно опубликованном исследовании они обучили LLM на большом наборе данных о маршрутах такси в Нью-Йорке. LLM должна была построить внутреннюю карту для проведения прогнозов. Эта карта имеет мало сходства с реальными городскими улицами, содержит невозможные дороги или летает над другими дорогами.
«Поскольку эти трансформеры не могут восстановить реальную карту улиц Нью-Йорка, они хрупки для последующих задач. Хотя иногда у них есть удивительные способности планирования маршрута, их производительность ухудшается при введении объездов.»
Люди используют язык как свою первую форму коммуникации и передают плотное количество информации. Безусловно, в языке можно выучить некоторые паттерны, и может возникнуть некоторое представление. Интуитивно трудно научиться рассуждать, подражая кому-то другому. Хотя также верно, что наличие внутреннего паттерна фундаментально для AGI, у людей внутренний паттерн постоянно обновляется сенсорной информацией, поступающей извне (тогда как LLM не могут функционировать в непрерывном обучении). По мнению некоторых исследователей, интеграция системы обратной связи могла бы стать первым шагом в улучшении внутренней модели LLM.
Хотя многие исследователи уверены, что внутренняя модель является ключом к AGI, вероятно, потребуются и другие элементы. Например, даже если бы возникла внутренняя модель, адекватно отражающая реальный мир, потребовались бы превосходные возможности восприятия (для обновления модели) и рассуждения (для использования внутренней модели для задач). Другие исследователи говорят, что многие особенности познания не могут возникнуть, если модель не может исследовать мир (воплощенное познание). Без физического присутствия модель не могла бы узнать определенную информацию о физическом мире.
Сэм Альтман утверждает, что AGI появится в 2025 году. Однако, похоже, он имеет в виду использование инструментов LLM для решения сложных проблем. Системы агентов, которые уже существуют, просто будут запущены в производство, но это не AGI (или, по крайней мере, не то, как научное сообщество его понимает). Сегодняшние LLM не способны к тем навыкам, которые необходимы для AGI: рассуждению и творчеству. Особенно теперь, когда преимущества масштабирования кажутся уменьшенными, это даже не кажется правильной технологией для достижения цели.
Модель мира кажется незаменимой для AGI, но, похоже, этого недостаточно. Воплощение могло бы помочь ИИ улучшить эту внутреннюю модель. Все еще не хватает архитектурных и теоретических инноваций для создания AGI.