Детекторы ИИ. Надевайте бейджик «бот», даже если вы человек
Вас когда-нибудь называли ботом, хотя вы клянетесь, что вы человек? Если вы проводили хоть немного времени за чтением статей в Интернете, то наверняка видели, как кто-то обвинял автора в использовании ИИ. Поскольку детекторы ИИ стали широко доступны, а использование ИИ растет, это становится слишком распространенным явлением. Но что происходит, когда эти детекторы ошибаются? Чтобы понять это, нам сначала нужно разобраться в том, как они работают.
Наука (или ее отсутствие)
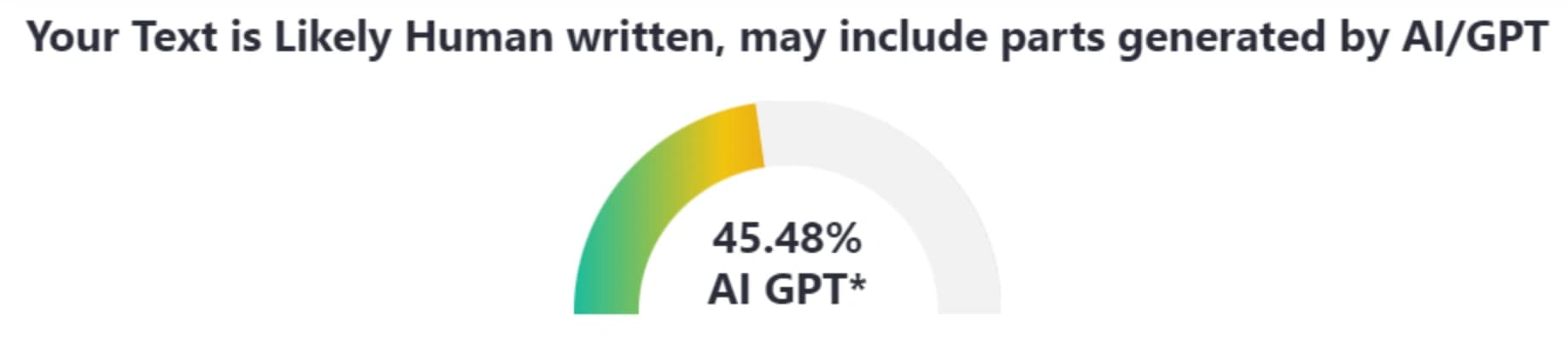
Детекторы ИИ не обладают экстрасенсорными способностями. Они полагаются на закономерности, сложность, данные и тщательный статистический анализ, чтобы отличить контент, созданный человеком и ИИ. По сути, они ищут предсказуемость в тексте.
Детекторы начинают с обучения работе с данными. Они получают огромное количество текстовых материалов, как от людей, так и от ИИ, что позволяет им выявить цифровые «отпечатки» контента, созданного машиной. Это помогает им изучить выбор слов, структуру и стиль.
Однако эти детекторы могут быть необъективными. Если набор данных, на котором они обучаются, состоит из формальных или академических текстов, им может быть сложно точно оценить непринужденный или творческий контент. Это все равно, что пытаться оценить творческий рассказ, используя в качестве рубрикатора техническое руководство. Разнообразие данных имеет значение – как и в реальном мире. Ограниченный или устаревший набор данных может привести к серьезным ошибкам, подобно тому, как учитель, объясняя современные концепции, полагается на старый учебник.
Проблема устаревших данных
Еще одна проблема заключается в поддержании наборов данных в актуальном состоянии. По мере быстрого развития инструментов для написания текстов и ИИ детекторы ИИ могут отставать, если их обучающие данные не обновляются достаточно быстро. Представьте себе, что вы просите свою бабушку рассказать вам, что сейчас в тренде на TikTok – без свежих, актуальных данных эти детекторы будут точно так же потеряны. Они могут выполнять свою работу только в том случае, если их постоянно обновляют с помощью новых стилей письма и достижений в области ИИ.
Человек, ИИ и подсознательная игра в подражание
Детекторы ИИ полагаются на распознавание «типичных» человеческих стилей письма. Но вот в чем загвоздка – люди являются естественными подражателями. Мы учимся и общаемся, копируя шаблоны. Чем больше мы взаимодействуем с ИИ (через генерируемые статьи или инструменты редактирования), тем больше мы можем неосознанно копировать его стиль. Вполне возможно, что мы можем подсознательно написать статью, повторяющую контент, созданный ИИ, даже не осознавая этого.
Распознавание образов
Контент, генерируемый ИИ, часто следует предсказуемой схеме, основанной на вероятности. Но что происходит, когда человек пишет высокоорганизованную, структурированную статью или пишет в профессиональной или академической среде? Детекторы могут быть введены в заблуждение такими распространенными фразами, как «в заключение» или «в результате», которые часто используются в официальных письмах. Детекторы отмечают их как сгенерированные ИИ, в то время как на самом деле это обычные человеческие фразы, написанные в определенном тоне или для определенной аудитории.
Засоряем ли мы данные?
Представьте себе такую ситуацию: Вы читаете статью, не подозревая, что она частично сгенерирована ИИ, и позже пишете собственную статью в блоге, вдохновившись ею. Теперь вы находитесь под влиянием ее стиля и структуры. Если детекторы ИИ уловят эту закономерность, они могут принять вашу статью за сгенерированную ИИ. И в каком-то смысле они не совсем ошибутся – вы подсознательно подражали чему-то, созданному ИИ.
Статистические модели – больше математика, чем магия
Эти детекторы работают, как прилежные бухгалтеры, подсчитывая цифры. Они анализируют длину предложения, выбор слов и структуру, но они не понимают нюансов человеческого творчества. ИИ-детекторы не понимают смысла или творческого подхода - они натренированы на шаблонах и математике.
Слишком отточенный или слишком простой - ловушка ИИ
Вот в чем загвоздка: если ваш текст слишком отшлифован, ИИ-детектор может предположить, что он был создан машиной. Инструменты ИИ, как правило, создают контент, который грамматически безупречен и логически структурирован. Детектор может подумать: «Вы слишком совершенны, чтобы быть человеком», и записать вас в ИИ. С другой стороны, если ваш текст слишком повторяется или жесткий, он также может быть отмечен как похожий на механическую предсказуемость – то, чем славились старые модели ИИ.
Это создает дилемму для авторов, которые чувствуют себя в ловушке – что бы они ни делали, их обвиняют в том, что они ИИ. Некоторые могут избегать использования инструментов искусственного интеллекта для улучшения своих произведений, опасаясь, что их сочтут мошенниками. Этот страх может удерживать писателей от использования мощных инструментов, которые могут улучшить их работу.
Реальные казусы с ИИ-детекторами
Мы все слышали эти ужасные истории. Представьте себе, что вы публикуете статью, а вас обвиняют в том, что вы обманули систему с помощью ИИ. Писатели были отмечены, их авторитет был поставлен под сомнение, их работа дискредитирована, и все это из-за неисправного детектора. Люди теряли возможности, удаляли свои статьи или даже сталкивались с проблемами на работе из-за того, что, по сути, является догадкой машины. А поскольку детекторы ИИ не являются непогрешимыми, неудивительно, что число таких проблем только растет. Помните детектор лжи? Да, примерно такой же уровень точности.
Предвзятость ИИ – скрытая проблема
Детекторы также могут проявлять предвзятость в зависимости от того, как они были обучены. Если система обучалась на более формальном или академическом материале, то творческий контент или случайная писанина могут быть несправедливо отмечены. По сути, если вы не пишете как энциклопедия, на вас может появиться значок «бот». Писатели, работающие в специфических жанрах – таких как поэзия или художественная литература - могут подвергнуться еще большему риску, поскольку их стиль нарушает традиционные формы, которых ожидают детекторы. И дело не только в стиле – детекторы ИИ также могут не справляться с незападными диалектами, что приведет к еще более несправедливому навешиванию ярлыков.
Юридические и профессиональные последствия
Теперь давайте задумаемся о том, как это влияет на карьеру. Представьте себе писателя-фрилансера или ученого, чьи средства к существованию зависят от авторитета. Если ИИ-детектор отметит вашу работу неверно, это может привести не просто к неловкости – это может стоить вам работы, клиентов или возможностей публикации. Мы говорим о реальных последствиях, основанных на неправильной интерпретации машиной Вашей работы.
Есть ли решение?
Итак, как же нам исправить ситуацию? Во-первых, детекторы ИИ нуждаются в серьезной модернизации в плане разнообразия. Они должны быть ознакомлены с более широким спектром стилей, жанров и культурных контекстов. Так они будут менее склонны к предвзятости. Во-вторых, крайне важен человеческий контроль. Хотя машины хорошо справляются с выявлением шаблонов, только человек может по-настоящему оценить творческий подход и нюансы. Детекторы могут служить инструментом, но не окончательным судьей.
Человек + ИИ – будущее писательской деятельности
ИИ уже здесь, и мы будем продолжать сотрудничать с этими инструментами. Но по мере того, как ИИ все больше интегрируется в наши писательские процессы, нам необходимо переосмыслить, что вообще значит «человеческое письмо». Эти детекторы должны развиваться, чтобы отразить это. Будущее письма может выглядеть как смесь – танец между человеческим творчеством и точностью, поддерживаемой ИИ. Это нормально. Нам просто нужно убедиться, что детекторы не отстают.